
GPT-5.5が示すコンピュータ作業の新しい進め方
2026年4月23日、OpenAIは最新モデル「GPT-5.5」を発表した。
GPT-5.5の本質は、与えられた質問に答えるだけでなく、目的に合わせて段取りを組み、作業を前へ進める力にある。
OpenAIはGPT-5.5について、これまでで最も高性能で直感的に使えるモデルであり、コンピュータでの仕事の進め方を変えるモデルとしている。
性能面では、前モデルの「GPT-5.4」と同等のレイテンシを維持しながら、ほぼすべての評価指標で性能を高めている点が特徴だ。つまり、速度を犠牲にして高性能化したのではなく、使い勝手を保ったまま、推論力やタスク遂行力を引き上げている。
そのうえで、今回の進化を最も象徴しているのが、エージェント機能の強化だ。
GPT-5.5は複雑な目標を理解し、必要な手順を自ら組み立て、ツールを使いながら作業を進め、途中で結果を確認し、タスクを完了まで遂行する力が高められている。
従来のAI活用では、ユーザーが細かく指示を分け、出力を確認し、次の作業を再度依頼する必要があった。
しかしGPT-5.5では、調査、整理、作成、検証といった複数工程を一連の流れとして扱いやすくなっている。
これは、コンピュータ上の作業を人間が逐一操作するのではなく、AIに目的を伝え、AIが実行プロセスを管理する新しい使い方を示すものだ。
特に、コーディング、データ分析、資料作成、オンライン調査、業務文書の作成など、実務に近い領域で効果を発揮しやすい。
たとえば、単に文章を生成するにとどまらず、必要な情報を集め、構成を考え、成果物を作り、内容の整合性を確認する流れまで担える点に進化の本質がある。
AIは作業の一部を補助する存在から、目的達成までの流れを支える存在へと役割を広げつつある。もちろん、すべての作業を完全に任せられるわけではなく、出力の確認や最終判断は依然として人間側に求められる。
それでも、GPT-5.5の進化は、AIが単なる回答ツールから、自律的に作業を前へ進める実務パートナーへ近づいたことを示している。
本記事では、実際の検証をもとに、GPT-5.5のエージェント機能がどのように進化し、自律実行型AIとしてどこまで実務に使えるのかを解説する。
ベンチマークで見るGPT-5.5の実力
GPT-5.5の進化を具体的に見るうえで、各種ベンチマークは重要な手がかりになる。
OpenAIはGPT-5.5について、前モデルのGPT-5.4と同等のレイテンシを維持しながら、ほぼすべての評価指標で性能を高めたとしている。
速度を落とさず、推論力、コーディング能力、ツール活用力、業務遂行力を底上げした点が特徴だ。
特に注目すべきは、単なる知識量ではなく、実務に近いタスクで成果を出す力が伸びている点である。
本章では、OpenAIの公式リリースで示された主要指標のうち、GPT-5.5の進化を読み解くうえで重要なベンチマークを抜粋し、コーディング、業務タスク、コンピュータ操作、研究支援などの観点から実力を整理する。
主要9指標から読み解く旧モデル・競合モデルとの比較
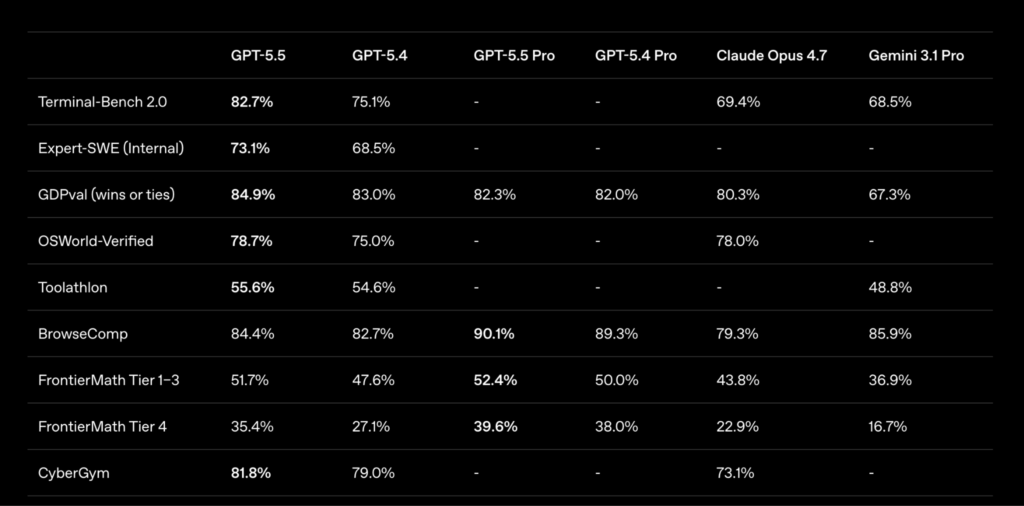
引用:OpenAI公式サイト
GPT-5.5の性能は、前モデルのGPT-5.4から幅広く底上げされている。
上記の表から分かるのは、コーディング、実務タスク、コンピュータ操作、ブラウジング、数学、サイバーセキュリティといった複数領域で改善が見られる点だ。
特に伸びが大きいのは、開発作業に関わる領域である。
複雑なコマンドライン作業を評価するTerminal-Bench 2.0では、GPT-5.5が82.7%を記録し、GPT-5.4の75.1%を7.6ポイント上回った。
Claude Opus 4.7の69.4%、Gemini 3.1 Proの68.5%と比べても高く、開発環境での実行力の強さが目立つ。
内部評価のExpert-SWEでも、GPT-5.5は73.1%と、GPT-5.4の68.5%から改善している。
実務タスクに近いGDPvalでは、GPT-5.5が84.9%を記録した。
GPT-5.4の83.0%、Claude Opus 4.7の80.3%、Gemini 3.1 Proの67.3%を上回っており、文書作成、調査、分析、資料化といった知的業務で高い汎用性を示している。
コンピュータ操作を測るOSWorld-Verifiedでも78.7%となり、GPT-5.4の75.0%やClaude Opus 4.7の78.0%を上回った。
これは、画面上の情報を理解し、操作手順を組み立てながら作業を進める能力が高まったことを示す。
一方、ブラウジング能力を測るBrowseCompでは、GPT-5.5が84.4%、GPT-5.5 Proが90.1%を記録した。
調査や情報収集のように複数の情報源を扱う作業では、Pro版の優位性も見える。
数学領域でもFrontierMath Tier 4でGPT-5.5は35.4%となり、GPT-5.4の27.1%から大きく改善した。
サイバーセキュリティ分野のCyberGymでも81.8%と、GPT-5.4の79.0%、Claude Opus 4.7の73.1%を上回っている。
全体として、GPT-5.5はGPT-5.4から劇的に別物になったというより、実務で重要な能力を広く引き上げたモデルだ。
OpenAIはGPT-5.5について、単に知能水準を高めただけでなく、問題解決の効率性も向上させたモデルとしている。
より少ないトークン数と少ない再試行回数で、高品質な出力を実現できる点が特徴だ。
実際、各種ベンチマークを見ると、開発、業務処理、コンピュータ操作、調査、技術的問題解決といった実務領域での伸びが目立つ。
では、こうした進化は他社モデルを含めた総合的な知能評価ではどの位置にあるのか。
次に、AIモデルの性能を横断的に比較する指標「Artificial Analysis Intelligence Index」をもとに、GPT-5.5の性能をより俯瞰して見ていく。
少ない出力でも高性能を示すGPT-5.5の効率性
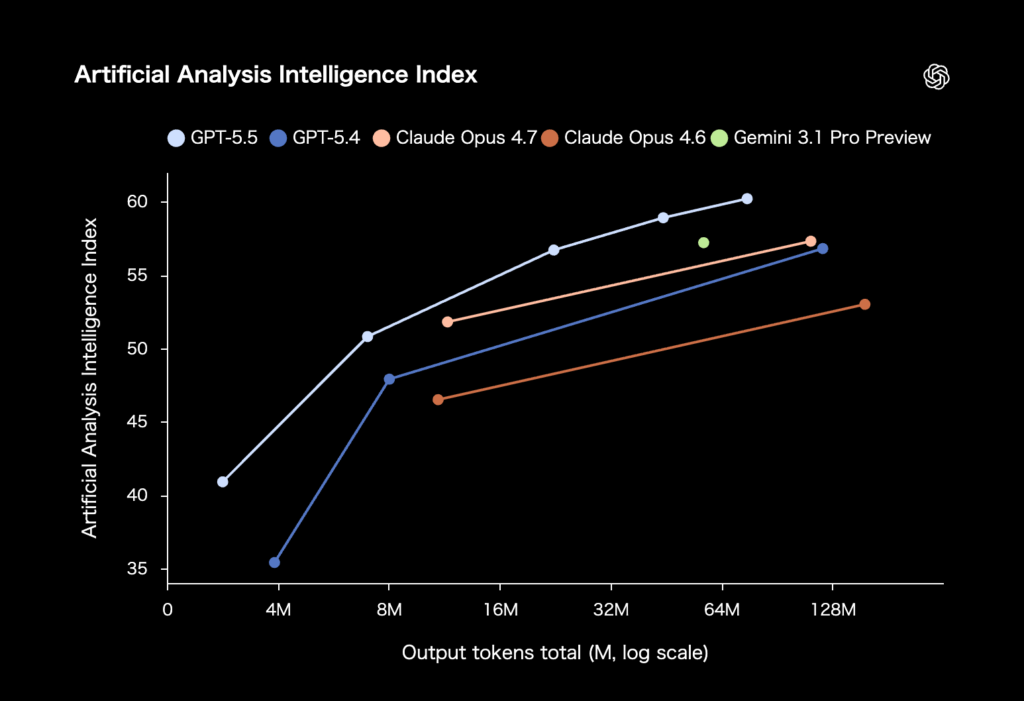
引用:OpenAI公式サイト
AIモデルの性能を横断的に比較する指標「Artificial Analysis Intelligence Index」を見ると、GPT-5.5の位置づけはさらに明確になる。
このグラフは、横軸に出力トークン量、縦軸に知能指数を置き、各モデルがどの程度の出力規模でどれだけ高い性能を出せるかを示している。
単にスコアが高いかどうかだけでなく、処理量に対してどれだけ効率よく性能を発揮できるかを見るうえで重要な指標だ。
グラフから読み取れるのは、GPT-5.5が全体を通じてGPT-5.4を上回っている点だ。
特に、出力トークン量が少ない領域では差が大きく、GPT-5.5は限られた処理量でも高い知能指数を示している。
これは、長い出力や何度もの試行に頼らなくても、意図を的確に捉え、効率よく回答や作業を進められる可能性を示している。
実務利用では、長く考えさせなければ成果が出ないモデルよりも、限られた出力で質の高い結果を返せるモデルの方が扱いやすい。
その意味で、GPT-5.5は単に性能が上がっただけでなく、実用面での効率も改善しているといえる。
他社モデルと比較しても、GPT-5.5の優位性は目立つ。Claude Opus 4.7は高い水準を示しているものの、同程度の出力トークン量ではGPT-5.5の方が上に位置している。
Gemini 3.1 Pro Previewも高い性能を示しているが、グラフ上ではGPT-5.5に届いていない。
Claude Opus 4.6と比べると差はさらに大きく、GPT-5.5は現行の主要モデル群の中でも上位に位置していることがわかる。
また、GPT-5.5は出力トークン量を増やすほど知能指数も伸びており、スケーリングの余地がある点も重要だ。
短い出力でも高性能を発揮しつつ、より多くの出力を使う場面ではさらに性能を引き上げられる。
これは、軽い質問から複雑な調査、長文生成、複数工程のタスクまで、用途に応じて性能を発揮しやすいことを示している。
この結果から見ると、GPT-5.5は「高性能だが重いモデル」ではなく、「効率よく高い性能を出せるモデル」として評価できる。
前述のベンチマークで示されたコーディング、業務処理、コンピュータ操作の強化に加え、総合的な知能評価でもGPT-5.4や競合モデルを上回る位置にある。
つまりGPT-5.5の進化は、個別タスクのスコア改善にとどまらず、実務で使ったときの判断力、処理効率、作業継続力の向上として表れている。
その他にも、GPT-5.5ではエージェント型コーディング、コンピュータ操作、ナレッジワーク、推論効率、安全対策といった領域でも進化が示されている。
特に重要なのは、これらの強化が個別の性能向上にとどまらず、「複雑な作業を理解し、ツールを使い、自ら確認しながら完了まで進める」というGPT-5.5の方向性とつながっている点だ。
ここからは、公式リリースで示された内容から主要なポイントを抜粋し、実務利用との関係を見ていく。
エージェント型コーディングの強化
GPT-5.5の進化が特に表れているのが、エージェント型コーディングだ。
OpenAIはGPT-5.5を、同社の中で最も強力なエージェント型コーディングモデルと位置付けている。Terminal-Bench 2.0では82.7%、SWE-Bench Proでは58.6%を記録し、Expert-SWEでもGPT-5.4を上回った。
重要なのは、いずれの評価でもGPT-5.4より高いスコアを出しながら、使用トークン数を抑えている点だ。
この強化は、単にコードを生成する力にとどまらない。Codex上では、実装、リファクタリング、デバッグ、テスト、検証まで幅広い開発作業を担えるとしている。
さらに、大規模なコードベースの文脈を保ち、曖昧な不具合の原因を推論し、ツールで前提を確認しながら周辺コードまで変更を反映する力が高まっている。
つまりGPT-5.5は、指示されたコードを書くAIではなく、開発上の問題を把握し、修正の着地点まで考えるAIへ近づいている。
コンピュータ操作とナレッジワークの強化
コーディングで示された強みは、日常的なコンピュータ作業にも広がっている。
OpenAIは、GPT-5.5がユーザーの意図をより正確に理解し、情報収集、重要点の把握、ツール利用、出力確認、素材の成果物化までを自然に進められるとしている。
Codexでは、文書、スプレッドシート、スライド作成においてGPT-5.4を上回り、業務調査や表計算モデル、雑多なビジネス情報を計画に変換する作業でも高い評価を得た。
数値面でも、知的業務を測るGDPvalで84.9%、実際のコンピュータ環境を自律操作できるかを測るOSWorld-Verifiedで78.7%、複雑な顧客対応フローを測るTau2-bench Telecomで98.0%を記録している。
これは、GPT-5.5が単なる文章生成や要約にとどまらず、画面上の情報を読み取り、操作し、複数ツールをまたいで成果物に近づける能力を高めたことを示している。
推論効率と安全対策の強化
GPT-5.5の進化で見逃せないのが、推論効率の向上だ。
OpenAIは、GPT-5.5をGPT-5.4と同等のレイテンシで提供するために、推論システム全体を再設計したとしている。
GPT-5.5はNVIDIA GB200およびGB300 NVL72システム向けに共同設計、訓練、提供され、CodexとGPT-5.5自体がインフラ改善にも使われた。
たとえば、Codexが本番トラフィックのパターンを分析し、GPU上の処理を最適に分割・分散するヒューリスティックを作成した結果、トークン生成速度が20%超向上したと説明されている。
一方で、能力向上に伴い安全対策も強化された。OpenAIはGPT-5.5について、これまでで最も強力な安全対策とともに公開したとしており、内部・外部のレッドチーム、サイバーセキュリティと生物分野の追加評価、約200の信頼済み早期アクセスパートナーからのフィードバックを経てリリースした。
特にサイバー分野では、GPT-5.4より能力が一段上がったと評価しつつ、悪用リスクを抑えるために高リスク活動や機微なサイバー依頼への制御、反復的な不正利用への保護を強化している。
GPT-5.5は高性能化と同時に、実務利用に耐える管理体制も重視したモデルといえる。
ベンチマークを見る限り、GPT-5.5はGPT-5.4から大きく方向性を変えたというより、実務で必要になる判断力、作業継続力、ツール活用力を底上げしたモデルといえる。
重要なのは、この進化が数値上の改善にとどまらず、ユーザーが実際に作業を任せたときの使いやすさにつながるかどうかだ。
次章では、実際の使用例を通じて、GPT-5.5の性能を確認する。
実際の検証から読み解くGPT-5.5の進化
実際の使用感に入る前に、まずGPT-5.5をどの環境で使えるのかを整理しておきたい。
OpenAIの公式リリースによると、ChatGPTでは「GPT-5.5 Thinking」がPlus、Pro、Business、Enterpriseユーザー向けに提供されている。
より難しい質問や高精度な作業に向けた「GPT-5.5 Pro」は、Pro、Business、Enterpriseユーザーが利用できる。
Codexでは、Plus、Pro、Business、Enterprise、Edu、GoプランでGPT-5.5を利用でき、40万トークンのコンテキストウィンドウにも対応する。
また、GPT-5.5はChatGPT上のThinkingだけでなく、API経由でも利用できる。
OpenAIは2026年4月24日の更新で、GPT-5.5とGPT-5.5 ProがAPIで利用可能になったと発表している。
APIでは、gpt-5.5は100万入力トークンあたり5ドル、100万出力トークンあたり30ドルで提供される。
なお、GPT-5.4は100万入力トークンあたり2.50ドル、100万出力トークンあたり15ドルであり、GPT-5.5ではAPI料金が入力・出力ともにGPT-5.4の2倍に引き上げられている。
GPT-5.5はChatGPT上で高度な推論を行う「Thinking」として使えるだけでなく、開発者が自社サービスや業務システムに組み込むAPIモデルとしても利用できる。
一方で、API利用では性能向上に応じてコストも上がっているため、実際に使う際は精度や作業効率の向上が料金差に見合うかも重要な判断材料になる。
本章では、こうした利用環境を前提に、実際にGPT-5.5を使った際にどのような変化を感じたのかを見ていく。
なお、本検証ではChatGPT上で利用できる「GPT-5.5 Thinking」を使い、数学問題、スライド生成、旅行プラン作成を実際に試用した。
ChatGPTでGPT-5.5 Thinkingを使う方法
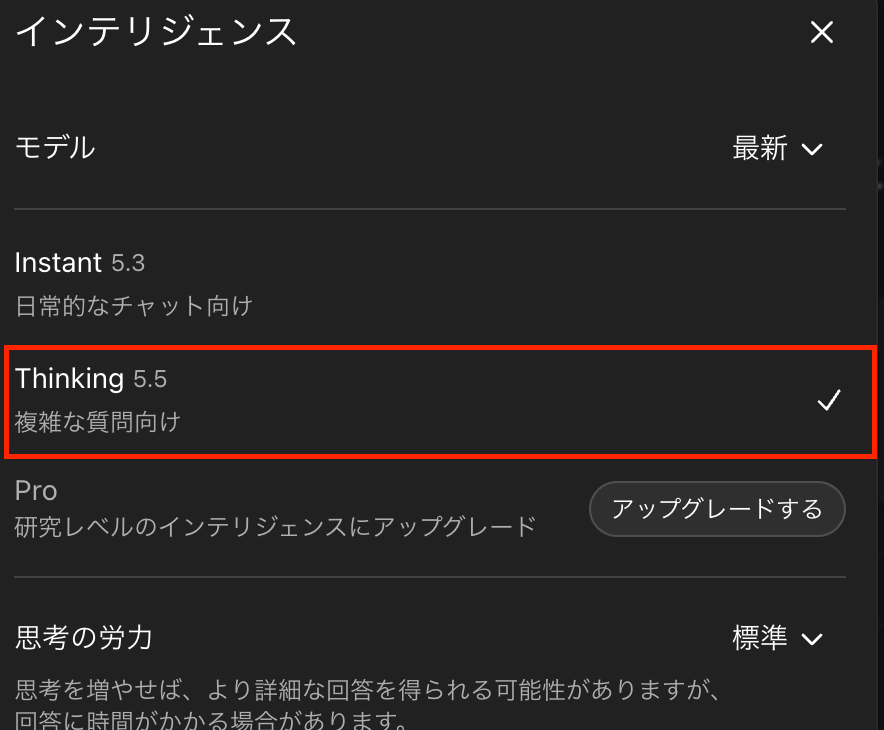
ChatGPT上でGPT-5.5 Thinkingを利用する方法はシンプルだ。
まずChatGPTにアクセスし、画面上部に表示されるモデル選択メニューを開く。
利用可能なモデル一覧の中から「GPT-5.5 Thinking」を選択すれば、そのままGPT-5.5 Thinkingを使った対話を開始できる。
引用:ChatGPT
GPT-5.5 Thinkingでは、用途に応じて「思考の労力」を調整できる点も特徴だ。
これは、AIにどの程度じっくり考えさせるかを指定する設定である。
軽い質問や短い文章作成では低めに設定し、複雑な調査、長文構成、比較検討、コード確認などでは高めに設定することで、より丁寧な推論を引き出しやすくなる。
モデルを切り替えた後は、普段と同じように質問や依頼を入力するだけでよい。
特別な操作は必要ないが、難しい作業を依頼する場合は、目的、条件、出力形式を具体的に伝えると精度が安定しやすい。
東大数学で試すGPT-5.5 Thinkingの推論力
まず、GPT-5.5 Thinkingの推論力を確かめるため、2026年度前期日程で出題された東京大学の数学問題を解かせてみた。使用した問題は以下である。

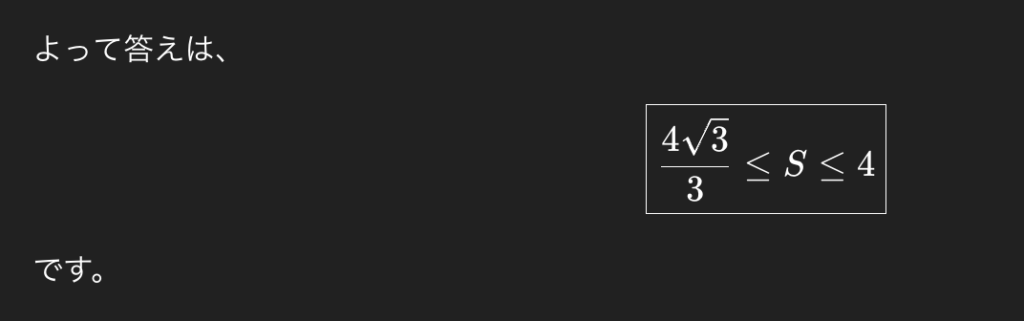
証明までの過程はここでは省略するが、GPT-5.5 Thinkingに解かせたところ、最終的な答えとして「4√3/3≦S≦4」を導き、正答に到達した。
この検証から見えたのは、GPT-5.5 Thinkingが複雑な問題に対して、段階的に考える力を高めているという点だ。
特に、問題文の条件を読み取り、どの変数に注目すべきかを判断し、必要な計算へつなげる流れは安定していた。
もちろん、数学問題では最終的な答えだけでなく、途中式や論理の正しさを人間が確認する必要はある。
それでも、東大数学のように複数の条件を扱う問題で正答に到達できたことは、GPT-5.5 Thinkingの推論力を示す一例といえる。
スライド生成で検証するGPT-5.5 Thinkingの資料作成力
次に、GPT-5.5 Thinkingの資料作成力を検証するため、GPT-5.4とGPT-5.5の違いを1枚のスライドにまとめさせた。
使用したプロンプトは「GPT-5.4と5.5の変化を3つの要点に絞って、スライドを生成して」である。
テーマは「GPT-5.4からGPT-5.5で変わった3つのこと」で、今回は進化点を「自律実行力」「実務性能」「推論効率」の3つに絞り、1枚で内容が伝わる比較スライドの生成を試した。
出典:ChatGPT
生成されたスライドでは、上部に「質問に答えるAIから、作業を進めるAIへ」という補足が入り、全体のメッセージが明確に整理されていた。
情報量が多いテーマでありながら、読者が視線を動かしながら理解しやすい構成になっていた点は評価できる。
従来の画像生成によるスライドでは、日本語の文字が崩れたり、文意が不自然になったりするケースが少なくなかった。
しかし、今回生成されたスライドでは、日本語の可読性が大きく改善されており、1枚の資料として、かなり完成度の高い仕上がりになっていた。
加えて、スライド内で示された「自律実行力」「実務性能」「推論効率」という整理や、主要ベンチマークの数値にも大きな誤りは見られず、内容面でもそのまま検証素材として使える水準だった。
特に分かりやすかったのは、GPT-5.5の進化を単なる性能向上としてではなく、作業の進め方の変化として表現していた点だ。
たとえば、「自律実行力」の欄では、GPT-5.4を「指示ごとに進める支援型」、GPT-5.5を「計画、ツール利用、実行、確認まで一貫しやすい」と整理していた。これにより、GPT-5.5が“回答するAI”から“作業を進めるAI”へ近づいていることが視覚的に伝わる。
また、「実務性能」の欄では、Terminal-Bench 2.0、Expert-SWE、OSWorld-Verifiedの数値を使い、GPT-5.4からGPT-5.5への改善を簡潔に示していた。
単に文章で説明するだけでなく、数値をミニバーのように見せることで、性能差を直感的に把握しやすくしている。
資料作成において重要な「要点の抽出」と「視覚化」がある程度できている印象だ。
一方で、完全にそのまま公開できる水準かというと、細部の確認は必要である。
たとえば、注釈の日付や表現の正確性、数値の出典表記、細かな文言の自然さは、人間側でチェックした方がよい。
生成AIによるスライドは、構成案や初稿としては有用だが、最終資料として使うには事実確認と表現調整が欠かせない。
それでも、今回の検証では、GPT-5.5 Thinkingが複雑な情報を1枚のスライドに整理し、見出し、比較軸、数値、結論までまとめられることが確認できた。
特に、文章だけでは伝わりにくいモデル間の違いを、カード型のレイアウトや図解で見せられた点は大きい。
資料作成においても、GPT-5.5 Thinkingは単なる文章生成にとどまらず、情報を構造化し、読者に伝わる形へ整える力を高めているといえる。
エージェント機能で旅行プランを作成
最後に、GPT-5.5 Thinkingのエージェント機能がどこまで自然に作業を進められるのかを確かめるため、簡単な旅行プランの作成を依頼した。
今回使用したプロンプトは、「東京から日帰りで行ける温泉地を3つ調べ、移動時間、予算、見どころを比較して、最もおすすめのプランを提案して」である。
あえて現在地や細かな条件は詳しく指定せず、「東京から日帰り」「温泉地を3つ」「移動時間、予算、見どころを比較」「おすすめを提案」という大まかな目的だけを渡した。
これは、GPT-5.5 Thinkingが曖昧さを含む依頼に対して、必要な情報を整理し、比較軸を設定し、最終的な提案まで進められるかを見るためだ。
単なる旅行先の候補を列挙するだけなら、従来のAIでも対応できる。
しかしエージェント機能で見たいのは、候補を調べ、比較し、条件に合う選択肢を絞り込み、理由とともに提案できるかである。
旅行プランは身近な題材でありながら、情報収集、条件整理、比較、判断という複数の工程を含む。
そのため、GPT-5.5 Thinkingが「質問に答えるAI」から「目的に沿って作業を進めるAI」へ近づいているかを確認しやすい検証材料になる。
| 温泉地 | 移動時間(目安) | 交通費(往復)* | 日帰り入浴の料金 | 見どころ/特徴 |
| 箱根湯本温泉(神奈川県) | 小田急ロマンスカーで新宿から約1時間25分。東京駅から新幹線利用の場合、東京~小田原約35分+箱根登山電車15分。 | 小田急ロマンスカーの運賃1,270円+特急料金1,200円(片道)→往復約4,940円。 | 『箱根湯寮』大浴場は大人平日1,700〜1,800円/土休日2,000〜2,200円。 | 箱根湯本は温泉街の活気と観光地の多さが魅力。泉質は肌に優しい単純温泉やナトリウム塩化物泉で美肌効果が期待される。箱根神社、彫刻の森美術館、大涌谷など周辺観光も充実。 |
| 熱海温泉(静岡県) | 東京駅から東海道新幹線「こだま」「ひかり」で約40〜50分。JR東海道本線なら約1時間40分。 | 新幹線自由席の正規料金は片道3,740円→往復約7,480円。普通列車なら片道約1,980円(時間は倍近く)。 | 『オーシャンスパ Fuua』の入館料は平日3,080円、小人2,310円。土日祝日は大人3,410円、小人2,530円。料金には館内着とタオルのレンタル代が含まれます。 | 海が望める温泉として有名。相模湾を望む露天立ち湯や岩盤浴、ラウンジがあり、夜は海岸通りのサンビーチがライトアップされる。熱海城や早咲きの梅園など観光も多彩。 |
| 鬼怒川温泉(栃木県日光市) | 浅草駅から東武特急「スペーシア」「リバティ」で直通約2時間。新宿・池袋からJR直通特急でも約2時間。 | スペーシアXの通常期・スタンダード席は運賃1,590円+特急料金1,940円→片道3,530円、往復約7,060円。 | 『鬼怒川温泉ホテル』の日帰り入浴は14:00〜17:00。料金は大人1,650円(入湯税別50円)、小人880円。 | 鬼怒川の渓谷沿いに大型ホテルが並ぶ温泉リゾート。アルカリ性単純温泉で美肌効果があり、露天風呂から四季折々の渓谷美が楽しめる。近くに船で川下りを楽しむ「鬼怒川ライン下り」や世界の建築物を再現した東武ワールドスクウェアなど観光スポットがある。 |
出力内容を見ると、温泉地の候補提示に加えて、比較表、各温泉地の特徴、おすすめプラン、モデルコースまで整理されていた。
さらに、作成した旅行プランはPDFやWord形式でダウンロードできるため、家族や友人との共有、印刷、後からの編集にも使いやすい。
単なるチャット上の回答にとどまらず、実際に旅行前の検討資料として扱いやすい点は利点といえる。
実際に使って特に印象的だったのは、回答までの流れが見えやすかった点だ。
回答完了までは5分程度で、GPT-5.4と比べても体感としてかなり出力速度が上がっているように感じた。
加えて、単に完成した文章が出てくるだけでなく、今どの工程を進めているのかが把握しやすく、情報収集、比較、判断、プラン作成という流れを追いやすかった。
これにより、もし自分の意図と異なる方向に進んでいた場合でも、途中で条件を追加したり、候補地を変えたり、予算を絞ったりといった軌道修正がしやすい。
この検証から見えたのは、GPT-5.5 Thinkingのエージェント機能が「調べて答える」だけでなく、「条件に沿って作業を進める」方向に進化していることだ。
旅行プランのような身近な題材でも、候補選定、比較表の作成、メリット・注意点の整理、最終提案、モデルコース化まで複数工程が含まれる。
GPT-5.5 Thinkingは、それらを一連の作業として処理し、読み手がそのまま検討材料にできる形までまとめていた。
一方で、完全にそのまま使えるかというと、人間側の確認は必要である。
交通費、営業時間、入浴料金は時期や曜日によって変わる可能性があり、実際に訪れる前には公式情報で再確認した方がよい。また、箱根湯本、箱根湯寮、大涌谷、箱根神社、彫刻の森美術館を1日で回るモデルコースは、日帰りとしてはやや詰め込み気味にも見える。
つまり、GPT-5.5 Thinkingのエージェント機能は「最終版を丸投げする」ものというより、短時間で精度の高いたたき台を作り、人間が最後に現実的な調整を加える使い方に向いている。
総じて、今回の旅行プラン作成では、GPT-5.5 Thinkingが目的を理解し、比較軸を設定したうえで、複数の情報を整理し、提案まで進める力を確認できた。
特に、回答工程の視認性が高く、途中で何をしているのか分かりやすい点は、エージェント機能を実用する際の大きな利点だ。
ユーザーが細かく手順を指定しなくても、目的に沿って作業を組み立ててくれる感覚があり、GPT-5.5 Thinkingが「質問に答えるAI」から「作業を前に進めるAI」へ近づいていることを実感できる検証だった。
実際に使って見えたGPT-5.5の実力と課題
ここまで見てきたように、GPT-5.5は単に回答精度を高めたモデルではなく、作業の進め方そのものを変える可能性を持つモデルだ。
ベンチマークでは、コーディング、業務タスク、コンピュータ操作、ブラウジング、数学、サイバーセキュリティといった複数領域でGPT-5.4を上回っており、総合的な性能の底上げが確認できた。
特に、同等のレイテンシを維持しながら、より少ないトークン数と少ない再試行回数で高品質な出力を目指せる点は、実用面で大きな進化といえる。
ChatGPT上のGPT-5.5 Thinkingを使った検証でも、その変化は確認できた。
東大数学の問題では、条件整理、式変形、面積計算、不等式処理を必要とする問題に対して、正答に到達した。
スライド生成では、GPT-5.4とGPT-5.5の違いを1枚の資料にまとめ、日本語の可読性や構成の完成度にも改善が見られた。
さらに、旅行プラン作成では、候補地の比較表、各温泉地の特徴、おすすめプラン、モデルコースまで出力し、情報収集から提案までを一連の作業として進められることが分かった。
とりわけ印象的だったのは、GPT-5.5が「質問に答える」だけでなく、「目的に沿って段取りを組む」方向へ進化している点だ。
ユーザーが細かく手順を指定しなくても、比較軸を設定し、必要な情報を整理して、成果物に近い形までまとめる力が高まっている。
これは、文章作成、調査、資料作成、企画のたたき台作成など、日常的な知的作業において大きな利点になる。
一方で、課題も残る。生成された内容は完成度が高くても、料金、営業時間、交通費、引用情報、数値データなどは人間側で確認する必要がある。
また、旅行プランのような実行を伴う提案では、行程がやや詰め込み気味になる場合もあり、現実的な調整は欠かせない。
スライド生成でも、日本語や構成は改善されたものの、最終資料として使うには表記や出典の確認が必要だ。
総じて、GPT-5.5は「丸投げすれば完全な成果物が出るAI」というより、「高品質なたたき台を短時間で作り、作業を大きく前進させるAI」と捉えるのが適切だろう。
人間が最終判断と確認を担う前提で使えば、GPT-5.5は調査、整理、生成、検証の各工程を効率化し、従来よりも作業全体を任せやすい存在になっている。
今回の検証を通じて、GPT-5.5は自律実行型AIとしての完成度を一段高めたモデルだと感じた。
今後は、AIに何を聞くかだけでなく、どこまで作業を任せ、どこまで人間が判断するのかを設計する力が、GPT-5.5を使いこなすうえで重要になりそうだ。
参考:
関連記事:
ChatGPT最新モデル「GPT-5.4」は実務性能が向上 進化の要点を実例で解説



