OpenAIは2026年5月5日、大規模なAIモデルの学習をより速く、安定して進めるための新しいネットワーク技術「MRC」を公開しました。MRCは、GPU同士がやり取りする大量のデータを複数の道に分けて送り、混雑や故障が起きても学習が止まりにくくなる仕組みです。ChatGPTを支えるような高性能モデルの開発では、1つの通信の遅れが全体の効率を下げるため、ネットワークの安定性がとても重要になります。
OpenAIはAMD、Broadcom、Intel、Microsoft、NVIDIAなどと協力し、MRCをOpen Compute Projectを通じて公開しました。AI開発を支える土台づくりに大きな意味を持つ取り組みであるため、本プロジェクトの詳細を考察します。
大規模AI学習でネットワークが重要になる理由
ChatGPTやCodexのようなサービスを支える高性能モデルを開発するには、膨大な数のGPUが同時に動くスーパーコンピュータが必要になります。GPUはAIの学習を進めるための計算装置ですが、ただ台数を増やせばよいわけではありません。多くのGPUが一つの大きなチームのように動くには、計算の途中で発生する大量のデータをすばやく送り合う必要があります。ここで大きな役割を持つのが、GPU同士をつなぐネットワークです。
大規模なAI学習では、1回の処理だけでも非常に多くのデータ転送が行われます。そのうち一つでも遅れると、ほかのGPUが待ち状態になり、全体の学習スピードが落ちる可能性があります。特に、多数のGPUが足並みをそろえて学習する方式では、どこか一部の遅れが全体に広がりやすくなります。
これまでのネットワークでは、通信の混雑や機器の不具合、接続の一時的な切断が起きると、学習処理が止まったり、復旧までに時間がかかったりすることがありました。大規模になるほど故障を完全になくすことは難しくなるため、故障が起きない前提ではなく、故障が起きても学習を続けられる設計が求められます。MRCは、そのための新しい仕組みとして注目されています。
参考:OpenAI「Supercomputer networking to accelerate large scale AI training」
MRCが目指した「止まりにくい」ネットワーク設計
MRCは、通信速度を上げるためだけの技術ではありません。大きな目的は、AI学習に必要なデータのやり取りを安定させ、混雑や故障が起きても処理を止めにくくすることです。OpenAIは、AMD、Broadcom、Intel、Microsoft、NVIDIAなどと協力しながら、GPU同士のデータ転送をより柔軟に扱える仕組みとしてMRCを開発しました。ここでは、MRCの特徴を3つの視点から整理します。
ひとつの通信を複数の道に分けて送ります
従来のネットワークでは、1つのデータ転送が基本的に1つの道を通る形が多く使われてきました。この方法はわかりやすい一方で、同じ道に通信が集中すると混雑が起きやすくなります。大規模なAI学習では、GPU同士が同時に大量のデータをやり取りするため、一部の道だけが混み合うと、学習全体の足を引っ張る可能性があります。
MRCでは、1つのデータ転送を多数の道へ分けて送ることで、特定の場所に負荷が集中しにくくしています。荷物を1本の道路だけで運ぶのではなく、複数の道路に分けて運ぶような考え方です。通信の遅れが一部に偏りにくくなり、多くのGPUが同じタイミングで進むAI学習を支えやすくなります。
10万を超えるGPU接続を見据えています
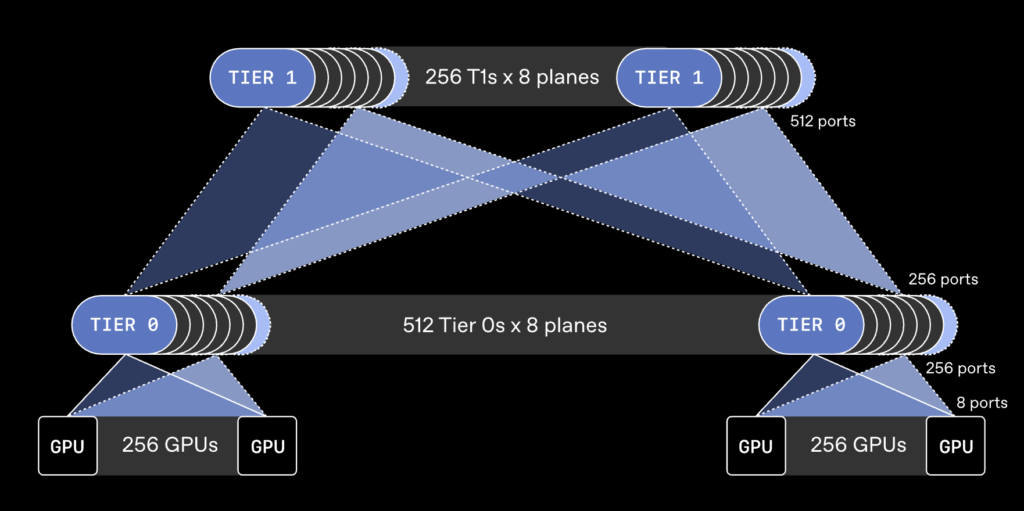
OpenAIが説明するMRCの重要な特徴の一つに、ネットワークを複数の面に分けて使う考え方があります。これは、1本の太い接続として扱うのではなく、複数の小さな接続に分け、並行するネットワークとして動かす仕組みです。たとえば800Gb/sのネットワーク接続を複数の100Gb/s接続として使うことで、より多くのスイッチやGPUをつなげる構成が可能になります。
OpenAIは、この方式によって10万を超えるGPUを2階層のスイッチでつなげると説明しています。一般的な構成では、より多くの階層や機器が必要になる場合があり、電力消費や故障しやすい場所も増えやすくなります。MRCは、規模を大きくしながらも、仕組みをできるだけシンプルに保つための設計だと考えられます。
故障を前提にしてすばやく避けます
大規模なスーパーコンピュータでは、接続や機器の不具合を完全になくすことは現実的ではありません。規模が大きくなるほど、どこかで一時的な通信不良が起きる可能性は高まります。重要なのは、故障をゼロにすることではなく、故障が起きても学習への影響を小さくすることです。
MRCは、通信の状態を見ながら、問題がありそうな道をすばやく避ける仕組みを持っています。データの一部が届かなかった場合には、その道に不具合がある可能性を見込み、別の道へ切り替えながら送り直します。OpenAIは、MRCが非常に短い時間で障害を避けられると説明しています。従来の仕組みでは復旧に時間がかかる場合もあるため、学習の停止や長い待ち時間を減らすうえで大きな意味があります。
MRCがAI開発の現場にもたらす実用面の変化
MRCの特徴は、技術的な新しさだけではありません。OpenAIは、MRCがすでに大規模なAI学習環境で使われていると説明しています。つまり、机上の構想ではなく、実際のAI開発を支える仕組みとして運用されている点に意味があります。ここでは、研究開発や運用チームにとってどのような変化があるのかを3つの視点で整理します。
学習作業が止まるリスクを減らせます
大規模AIの学習では、長い時間にわたって大量のGPUを動かし続けます。その途中でネットワークの一部に不具合が起きると、以前は学習作業が止まり、保存していた地点から再開する必要が生じることがありました。これは単なる待ち時間ではなく、高価なGPUの稼働時間を失うことにもつながります。
MRCでは、通信に問題が出た道を避けながら、別の道を使えるため、学習全体が止まるリスクを下げられます。OpenAIは、接続の一時的な不具合が複数回起きても、大規模な学習作業に大きな影響が見られなかった例を紹介しています。これは、AI開発の現場にとって、学習をより安定して続けられる可能性を示すものです。
保守作業の進め方が変わります
スーパーコンピュータの運用では、ネットワーク機器の点検や修理は避けられません。従来は、1本の接続を止めるだけでも学習作業への影響を考え、運用チームと学習を担当するチームが細かく調整する必要がありました。作業のタイミングを誤ると、学習が止まる可能性があったためです。
OpenAIは、MRCを使った環境では、リンク修理や一部スイッチの再起動について、以前ほど厳密な調整が不要になった例を挙げています。これは、ネットワークが壊れないことを前提にするのではなく、壊れても避けられる構造に変わったためだと考えられます。保守のたびに学習を止める必要が減れば、研究開発の流れを保ちやすくなります。
複数の学習作業を同じ基盤で動かしやすくなります
大規模なAI開発では、1つのスーパーコンピュータ上で複数の学習作業が同時に走ることがあります。このとき問題になるのが、ある作業の通信が混雑を生み、別の作業の速度にも影響してしまうことです。限られた計算資源をうまく使うには、複数の作業が同じ環境を使っても、互いに邪魔をしにくい設計が必要になります。
MRCは、データを多くの道に分けて送り、混雑している道を避けることで、ネットワーク全体の負荷をならしやすくします。OpenAIは、MRCによってネットワークの中心部分でほとんど混雑が見られなくなり、複数の作業が同じクラスターを共有しても互いの性能に影響しにくくなると説明しています。今後、AIモデルの開発数が増えるほど、1つの基盤を安定して共有できる仕組みの価値は高まると考えられます。
MRC公開が示すAIインフラ共通化への流れ
OpenAIがMRCを公開した意味は、自社のスーパーコンピュータ改善に加えて、AIインフラの共通基盤づくりにも広がる可能性があります。今回の取り組みでは、AMD、Broadcom、Intel、Microsoft、NVIDIAなどの企業と連携し、さらにOpen Compute Projectを通じて仕様を広く使える形にしています。これは、大規模AIを支えるネットワーク技術が、一部企業だけの閉じたノウハウではなく、業界全体で発展させる土台になりつつあることを示していると考えられます。
生成AIの性能向上には、モデルの工夫やデータの整備だけでなく、それを動かす計算基盤の進化が欠かせません。特に、10万を超えるGPUを安定して動かすような環境では、ネットワーク設計そのものがAI開発の速度を左右します。MRCは、通信を分散し、故障を避け、複雑な経路管理に頼りすぎない設計を取り入れることで、より大きな学習環境を扱いやすくする技術です。
また、仕様が公開されたことで、クラウド事業者、半導体メーカー、ネットワーク機器メーカーが共通の考え方をもとに開発を進めやすくなる可能性があります。
今後の展望
MRCは、大規模AI学習を支えるネットワークの新しい選択肢として公開されました。今後は、AIモデルの性能向上だけでなく、クラウド基盤の設計、運用保守、業界全体で使いやすい共通ルールづくりにも影響を広げていくと考えられます。ここでは、MRCの特徴から見えてくる今後の活用可能性を3つの視点で考察します。
AI学習基盤は「速さ」だけでなく「止まりにくさ」で選ばれるようになります
これまで大規模AIの開発では、GPUの性能や台数に注目が集まりやすい傾向がありました。しかし、OpenAIがMRCで示したのは、どれほど多くのGPUを用意しても、それらをつなぐネットワークが不安定であれば学習効率は大きく下がるという現実です。今後のAIインフラでは、単純な通信速度だけでなく、混雑や故障が起きたときにどれだけ学習を止めずに続けられるかが、より重要な評価軸になると考えられます。
特に、複数のGPUが足並みをそろえて進む学習では、一部の遅れが全体の遅れにつながります。そのため、MRCのように通信の道を分散し、問題がある道をすばやく避ける仕組みは、AI開発の生産性に直結します。今後はクラウド事業者やAI開発企業が、スーパーコンピュータを選ぶ際に「どのGPUを使っているか」だけでなく、「ネットワーク障害が起きたときに学習がどう守られるか」を重視する可能性があります。
保守しながら学習を続ける運用が広がる可能性があります
スーパーコンピュータの規模が大きくなるほど、接続や機器の不具合は避けにくくなります。従来は、ネットワーク機器の修理や再起動を行う際に、学習作業への影響を避けるため、関係するチーム同士で細かく調整する必要がありました。場合によっては、学習の一時停止や慎重な作業計画が必要になり、研究開発の流れを止める要因にもなっていました。
MRCの考え方が広がれば、こうした運用のあり方は変わる可能性があります。故障が起きても通信が別の道へ回り込み、影響を小さくできるなら、ネットワーク保守は「学習を止めないために避ける作業」ではなく、「学習を続けながら行う通常業務」に近づきます。OpenAIが紹介している実運用の例では、リンク修理や一部スイッチの再起動が、以前ほど学習チームとの調整を必要としなくなったとされています。
この変化は、運用チームの負担軽減にもつながります。大規模AIの開発現場では、研究者、インフラ担当者、クラウド運用者が密接に関わります。
公開仕様をもとにAIインフラの共通基盤づくりが進みます
MRCの大きな特徴は、OpenAIだけが使う内部技術として閉じていない点です。OpenAIは、AMD、Broadcom、Intel、Microsoft、NVIDIAなどと協力してMRCを開発し、Open Compute Projectを通じて仕様を公開しました。これは、AIインフラを一社だけで最適化するのではなく、半導体、クラウド、ネットワーク機器、AI開発企業が共通の土台を持つ方向へ進んでいることを示していると考えられます。
今後、AIモデルはさらに大きくなり、学習に必要な計算資源も増えていく可能性があります。そのとき、各社が別々の方式でネットワークを設計していると、機器の組み合わせや運用の知見が分かれやすくなります。一方で、MRCのような仕様が共有されれば、対応するネットワーク機器やクラウド基盤が増え、より多くの事業者が大規模AI学習に適した環境を作りやすくなります。
また、仕様公開は研究開発の透明性にもつながります。AIの性能向上は、モデルそのものだけでなく、それを支えるインフラの積み重ねによって実現されます。