
GPT-5.4で進化したChatGPTの実務性能 押さえたいポイント
2026年3月5日、OpenAIはChatGPTの最新モデル「GPT-5.4」をリリースした。
OpenAIはGPT-5.4を、より事実に強く、実務で使いやすいモデルとして打ち出しており、ユーザーが日常的にアプリやチャット形式で利用する対話型AIサービス「ChatGPT」では「GPT-5.4 Thinking」が導入された。
公式には、難しいタスクでより長く思考できる点に加え、スプレッドシート作成や資料構成、調査業務など、現実の仕事に近い作業への強さが強調されている。
さらに、従来のモデル「GPT-5.2」比で誤った主張の発生確率を33%低減、回答全体に誤りを含む確率を18%下げたとされ、ハルシネーションの抑制も大きな訴求点になっている。
こうしたアップデートの背景には、Claudeを中心とした競合AIの急速な台頭による競争環境の変化もあるとみられる。
一部メディアや市場関係者の間では、Claudeの台頭をきっかけに「SaaSの死」や「アンソロピック・ショック」といった表現まで現れ、従来の業務ソフトが生成AIに代替されるのではないかという見方も広がった。
Anthropicは金融向け展開も強めており、OpenAIにとっては実務での使いやすさを巡る競争がいっそう激しくなっている。
生成AIの競争軸が、単なる知能の高さから、業務でどれだけ使いやすく、信頼できるかへ移りつつあることを示す動きといえるだろう。
そうした競争環境の中で、OpenAIは「より賢いAI」ではなく、「より安心して仕事で使えるAI」を有料体験の中核に据え始めたように見える。
GPT-5.4 Thinkingは、2026年3月5日の公開時点でChatGPT Plus、Team、Pro向けに提供が始まり、EnterpriseとEduでは管理者設定から早期アクセスを有効化できる形で展開された。
Claudeなどが実務での使いやすさを武器に台頭する中、OpenAIは信頼性の高い実務向け体験を上位プランに集約し、ユーザーを囲い込む方向へ踏み込んでいるようにも見える。
では実際に、GPT-5.4が実務でどこまで使えるモデルへ進化したのかを、実例を交えながら見ていく。
GPT-5.4はどこが進化したのか ベンチマークから読み解く
GPT-5.4の進化を最も端的に示すのが、OpenAIが公開した各種ベンチマークの結果だ。
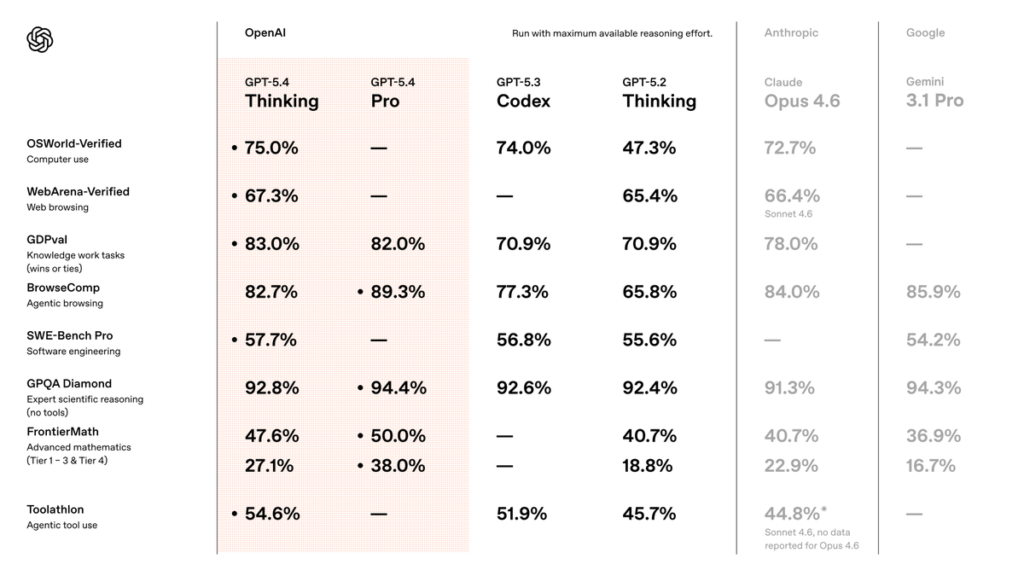
引用:OpenAI公式X
結論から言えば、GPT-5.4は全分野で圧倒的な首位を取るモデルというより、実務に直結する領域を重点的に強化した「バランス型の上位モデル」として進化したと見るのが適切だ。
今回の更新で目立つのは、単に難問を解く性能が伸びたというより、実際の仕事に近いタスクでスコアを伸ばしている点にある。
GPT-5.4で特に注目されるのが、ハルシネーションの抑制だ。
OpenAIは公式発表の中で、GPT-5.4を「これまでで最も事実性の高いモデル」と位置づけている。
さらに、ユーザーが事実誤りを指摘した匿名化済みプロンプト群で評価した結果、GPT-5.2と比べて「個々の主張が誤っている確率」は相対的に33%低下し、「回答全体に何らかの誤りが含まれる確率」も相対的に18%低下したという。
生成AIは便利である一方、もっともらしい誤答「ハルシネーション」を返す点が実務利用の壁になってきた。
その意味で、GPT-5.4の進化は単なる性能向上ではなく、業務で使ううえでの信頼性を底上げする改善として見るべきだろう。
OpenAIがGPT-5.4を業務用途向けモデルと位置づけていることは、各種ベンチマークの数字にも表れている。
知識業務を測る「GDPval」の進化
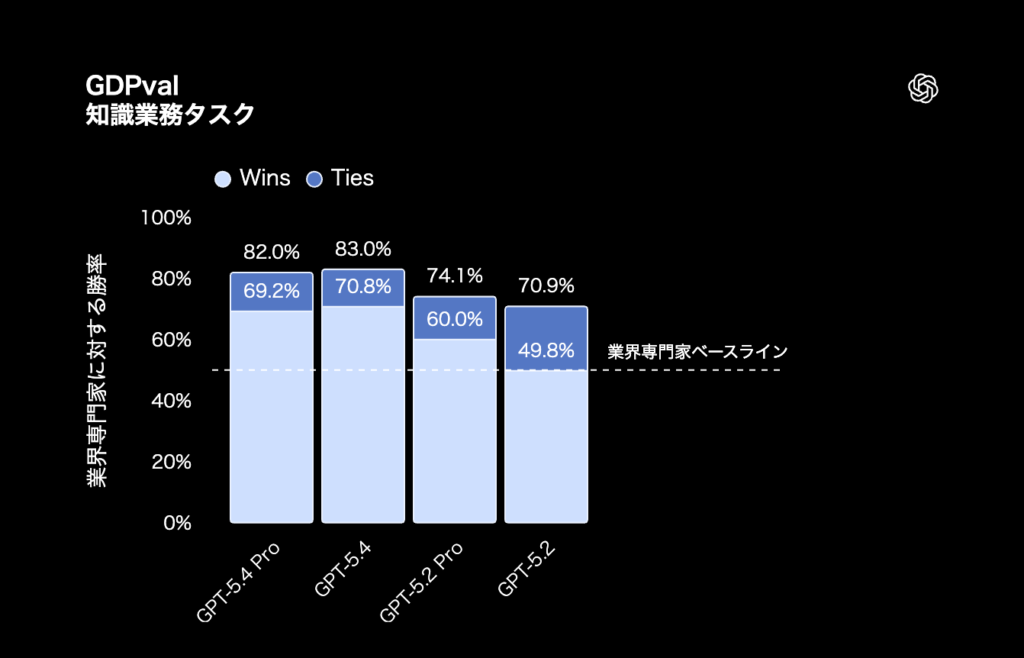
引用:OpenAI公式サイト
まず注目したいのが、知識業務を測る「GDPval」だ。
これは44職種にまたがる実務タスクで成果物を作れるかを測る指標で、営業用プレゼンテーションや会計スプレッドシート、救急診療のスケジュール、製造図面、短編動画など、現場に近いアウトプットが評価対象となる。
GPT-5.4はこのGDPvalで83%を記録し、GPT-5.2の71%を上回った。
OpenAIが今回、スプレッドシート、プレゼンテーション、ドキュメントの作成・編集能力の向上に重点を置いたとしていることを踏まえると、GPT-5.4の進化は「考える力」そのものだけでなく、「仕事として形にする力」の強化として捉えられる。
GPT-5.4のコンピュータ操作能力
同じ傾向は、PC操作やツール利用のベンチマークにも表れている。
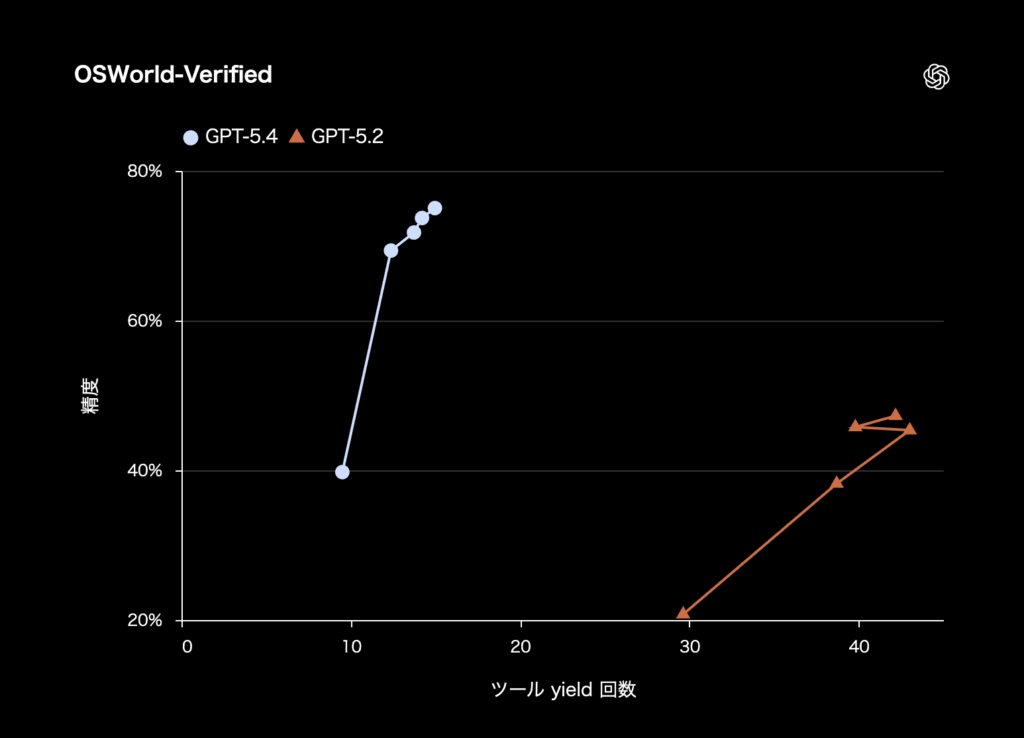
引用:OpenAI公式サイト
OSWorld-Verifiedでは75%となり、GPT-5.2 Thinkingの47.3%から大きく伸びた。
これは、単に文章を生成するだけでなく、コンピュータ上で実際の操作をこなす能力が強化されたことを意味する。
さらに、ツール利用能力を測るToolathlonでも54.6%と、GPT-5.2の46.3%を上回った。
OpenAIがGPT-5.4を実務向けモデルとして位置づけている背景には、こうした「ツールを横断して業務を遂行する力」の底上げがある。
ブラウジング関連のスコアも印象的だ。
WebArena-Verifiedは67.3%、BrowseCompは82.7%となり、いずれもGPT-5.2 Thinkingを上回っている。
ここから見えてくるのは、GPT-5.4 Thinkingがブラウジング特化で最強というより、検索、調査、ツール利用、文書作成を幅広く高水準でまとめた総合型だという構図である。
突出した一点突破ではなく、実務全体を安定して支える方向に寄せたモデルといえる。
SWE-Bench Proで見るコーディング性能の進化
ソフトウェア工学や高度推論でも改善は確認できる。
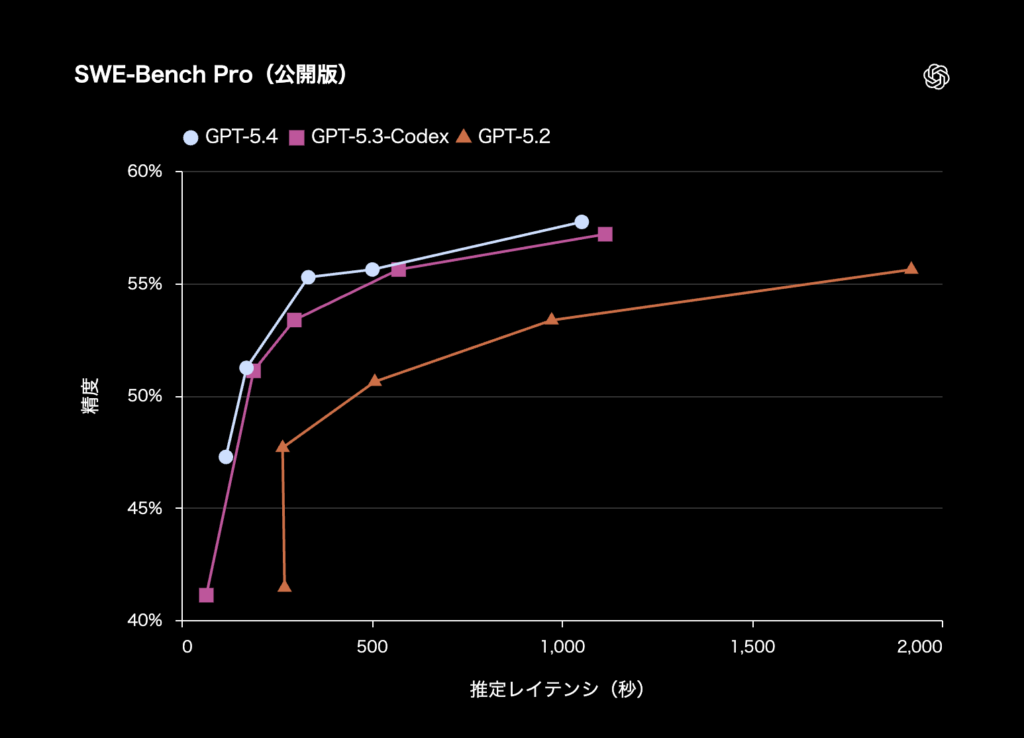
引用:OpenAI公式サイト
SWE-Bench Proの公開版グラフから見えるのは、GPT-5.4が単に最終スコアを伸ばしただけではない。グラフからは、短い待ち時間でも高い精度を出しやすくなったと見ることができる。
横軸は推定レイテンシ、つまり回答が返ってくるまでにかかる時間、縦軸は精度を示しており、GPT-5.4は全体としてGPT-5.3-CodexとGPT-5.2を上回る軌跡を描いている。
特に低レイテンシ領域での立ち上がりが良く、短時間でも実用的な精度に到達しやすい。
一方で、GPT-5.3-Codexとの差は圧倒的ではなく、OpenAIはコーディング性能を飛躍的に変えたというより、より効率よく高精度へ届く方向で改善したと見るのが妥当だ。
つまり、GPT-5.4の進化は、最高精度の上積み以上に、応答速度と精度のバランスが実務向けに最適化された点が特徴といえる。
ウェブ検索の強化
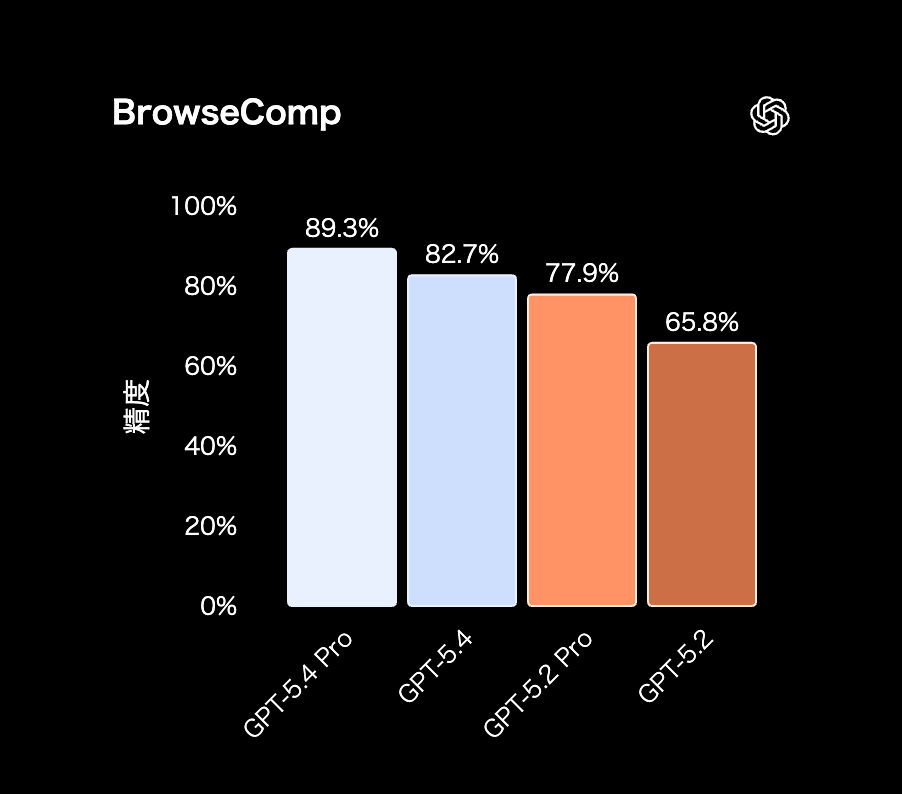
GPT-5.4で見逃せない進化のひとつが、ウェブ検索を含む調査能力の向上だ。
これを示すのが、ブラウジング性能を測るBrowseCompのスコアである。
GPT-5.4は82.7%を記録し、GPT-5.2の65.8%を大きく上回った。
注目すべきなのは、旧世代の上位モデルであるGPT-5.2 Proの77.9%も超えている点だ。
つまりGPT-5.4では、単に知識を答える力だけでなく、ウェブ上を探索しながら必要な情報を見つけ、整理し、答えに結びつける力そのものが底上げされたといえる。
この改善は、実務との相性が非常に良い。実際の仕事では、最初から答えを知っていることよりも、必要な情報にたどり着けるかどうかが重要になる場面が多い。
競合調査、市場分析、資料作成、要点整理といった作業では、検索の精度と情報の拾い方が成果物の質を左右する。
GPT-5.4がBrowseCompで大きく伸びたことは、こうした「調べながら考える」力が強化されたことを示す材料になる。
一方で、GPT-5.4 Proは89.3%とさらに高い水準にあり、通常版との差も見られる。
これらの結果からは、GPT-5.4が幅広い実務に対応する高水準のモデルである一方、より複雑で深い調査はProが担うという役割分担も読み取れる。
とはいえ、通常版のGPT-5.4でも旧世代のProを上回っている点は大きい。
ウェブ検索の強化は、GPT-5.4が単なる会話AIではなく、実務で使える調査支援ツールへ一段進んだことを示す進化といえる。
その他にも、GPT-5.4ではThinkingの使い勝手そのものが改善されている。
ChatGPTのGPT-5.4 Thinkingは、回答の冒頭で思考の進め方を示せるようになり、途中で方針を調整しやすくなった。
加えて、長い思考を要する質問でも文脈を保ちやすくなり、非常に具体的なクエリに対するウェブ調査能力も強化されている。
さらに、APIやCodexではネイティブのコンピュータ操作能力を備えた初の汎用モデルとなり、最大100万トークンのコンテキスト対応も打ち出された。
ただし、この長文コンテキストはAPIとCodex側の仕様であり、ChatGPTのGPT-5.4 ThinkingのコンテキストウィンドウはGPT-5.2 Thinkingから変更がない。
こうして全体を俯瞰すると、GPT-5.4の進化の方向性は明快だ。
強くなったのは、抽象的な知能の高さだけではない。
資料を作る、調べる、PCを操作する、ツールを使うといった、実際の仕事で問われる力が重点的に引き上げられている。
ベンチマークの数字は、GPT-5.4が単なる高性能モデルではなく、「実務で使えるAI」へと軸足を移したアップデートであることを示している。
GPT-5.4の料金プラン
GPT-5.4は、すべてのChatGPTユーザーが同じ条件で使えるわけではない。
無料版では基本的にGPT-5.3が中心で、GPT-5.4 Thinkingを明示的に使うにはGo以上の契約が必要になる。
さらに、同じ有料プランでも利用できるモデルや上限は異なり、最上位のGPT-5.4 ProはPro、Business、Enterprise、Edu向けとなっている。
つまり、GPT-5.4系は単なる新モデルではなく、どのプランでどこまで使えるかを把握しておくことが重要になる。
まずは、プランごとの利用条件を整理しておきたい。
なお、今回の表では無料版、Go、Plus、Proのみを掲載しており、その他の法人向けプランは割愛している。
| 無料版 | Go | Plus | Pro | |
| 月額料金 | 0ドル | 8ドル | 20ドル | 200ドル |
| GPT-5.4 Thinking | 基本不可 | 利用可 | 利用可 | 利用可 |
| GPT-5.4 Thinking の選択方法 | – | 入力欄の+からツールメニューでThinkingを選択 | モデルピッカーから手動選択 | モデルピッカーから手動選択 |
| GPT-5.4 Thinking の上限 | – | 5時間ごとに最大10件 | 週あたり最大3,000件 | 無制限 |
| GPT-5.4 Pro | 不可 | 不可 | 不可 | 利用可 |
| 上限到達後の挙動 | mini版に切替 | GPT-5.3はmini版に切替 | GPT-5.3はmini版に切替、Thinkingは選択不可になることがある | ガードレール範囲内で継続利用 |
| 備考 | GPT-5.3がデフォルト | Thinkingは手動有効化が必要 | GPT-5.2 Thinkingはレガシーとして一定期間残存 | GPT-5モデルへ無制限アクセス、不正利用防止ガードレールあり |
この表から分かる通り、GPT-5.4系は利用できるモデルや条件がプランごとに異なり、有料プランを中心に段階的に展開されている。
Goでは利用回数が限られ、Plusでも週あたりの上限が設けられている一方、ProではGPT-5.4 Thinkingに加えてGPT-5.4 Proまで無制限に近い形で利用できる。
つまり、GPT-5.4は単なるモデル更新というより、利用体験そのものをプランごとに差別化した設計になっているといえる。
とくに、GPT-5.4の性能を実務でしっかり試したい、あるいは継続的に活用したいのであれば、Plusプラン以上が有力な選択肢になるだろう。
なお、いきなりChatGPTの有料プランを契約するのが不安であれば、まずは外部サービスで使用感を確かめるという選択肢もある。
たとえば「天秤AI byGMO」は、複数の生成AIモデルを同時に比較できるサービスとして展開されており、無料プランも提供している。
「Genspark」は、AI検索やチャット機能に加え、プレゼン作成や会議メモなども一体的に利用できる総合型のAIワークスペースサービスであり、GPT-5.4も利用制限付きではあるが、無料で試すことができる。
もっとも、こうしたサービスで使える「GPT-5.4」は、ChatGPT公式で利用できる「GPT-5.4 Thinking」と同一ではない点に注意したい。
外部サービスではAPI経由で通常版のGPT-5.4を利用しており、ChatGPT内のThinkingモードのように、長く考えながら段階的に答えを組み立てる挙動とは異なる。
まずは天秤AIやGensparkでGPT-5.4を軽く試し、使い続けたいと感じた段階で、ChatGPT Plusなどの継続利用を検討するのも1つの手段だろう。
実例で確かめるGPT-5.4の実務性能
ここからは、GPT-5.4が実際の作業でどこまで使いやすくなったのかを、いくつかの実例をもとに確かめていく。
まずは、GPT-5.4 Thinkingを利用できるユーザー層を整理しておきたい。
2026年3月5日の公式発表時点では、ChatGPTでGPT-5.4 Thinkingを利用できるのはPlus、Team、Proで、EnterpriseとEduは早期アクセス方式だった。
現時点では対象プランや選択方法に一部更新が入っているが、5.4系の推論モデルを明示的に使えるのは主に有料プランのユーザーに限られる。
なお、筆者はChatGPT Plusユーザーであり、今回の検証は実際にGPT-5.4 Thinkingを用いて行っている。
では実際に、その性能は日々の仕事の中でどのように表れるのか。
次から具体的な作業例を通じて見ていきたい。
VTuber運営ANYCOLORの決算資料をGPT-5.4 Thinkingで読み解く
長文資料の整理精度を確かめる題材として、今回は2026年3月11日に発表された、VTuberグループ「にじさんじ」を運営するANYCOLORの決算説明資料を取り上げる。
ANYCOLORの決算説明資料は、数値、事業別内訳、リスク、見通しが一体的に示されており、生成AIの要約力と論点整理力を測る題材として適している。
とりわけANYCOLORの資料は、ライブ配信、コマース、イベント、プロモーションといった複数の収益源が並び、数値と事業説明が密接に関連している。
単純に要点を抜き出すだけでなく、どこが成長の牽引役で、どこに注意点があるのかを正確に整理できるかが問われる。
そこで本検証では、GPT-5.4 Thinkingにこの決算資料を読ませ、要点整理や重要論点の抽出をどこまで正確にこなせるかを見ていく。
なお、今回の検証で用いたプロンプトは、「ANYCOLORの決算資料をわかりやすく説明してください」というシンプルなものに設定した。

引用:ChatGPT
実際にANYCOLORの決算資料を読み込ませてみると、GPT-5.4 Thinkingの強みは、単に数字を抜き出すことではなく、複数の論点を整理しながら「この決算の本質は何か」を順序立てて説明できる点にある。
今回の出力では、まず全体像として「本業は強いが、在庫処理のコストで利益見通しが少し下がった」と要旨を提示している。
そのうえで、売上や営業利益の伸び、コマースとイベントの好調、棚卸資産評価損の計上、通期見通しの修正という順で論点を分解していた。
単なる箇条書きではなく、決算の読み方そのものに沿って情報を配置している点は、Thinkingモデルらしい特徴といえる。
もちろん、細部の分析まで完全に自動化できるわけではなく、最終的には人間による確認が必要だ。
ただ今回の結果を見る限り、GPT-5.4 Thinkingは長い決算資料を前にしても、数字、背景、リスク、見通しを順序立てて整理し、「何が起きた決算なのか」を読み手に伝わる形に再構成する力の向上が見られる。
決算資料のように情報量が多く、論点が散らばりやすい文書ほど、GPT-5.4 Thinkingの整理力の向上は表れやすい。
WBC侍ジャパンの最新戦績を正しく答えられるか GPT-5.4 Thinkingの正確性と検索力をテスト
ハルシネーションの抑制やウェブ検索機能の進化を確かめる題材として、今回は侍ジャパンの最新戦績を取り上げる。
スポーツの勝敗や順位は時点によって状況が変わるため、生成AIが過去の知識だけで答えると誤りが出やすい。
一方で、検索機能が適切に働けば、最新の試合結果や通過状況まで含めて整理できるはずだ。
特にWBCのように、本戦と強化試合を混同しやすいテーマでは、モデルが余計な情報を足さず、必要な事実だけを拾えるかが問われる。
そこで本検証では、GPT-5.4 Thinkingに2026年3月13日時点の侍ジャパンの戦績を尋ね、ウェブ検索を活用しながら、どこまで正確に最新状況を整理できるのかを見ていく。
なお、今回の検証で用いたプロンプトは以下の通りだ。
「2026年3月13日時点のWBCにおける侍ジャパンの戦績を教えてください。
ウェブ検索を使って最新情報を確認し、WBC本戦のみを対象に、対戦相手・勝敗・スコア・現在の順位または通過状況を整理してください。
強化試合や壮行試合は含めないでください。
回答は事実ベースで、400字以内にまとめてください。」
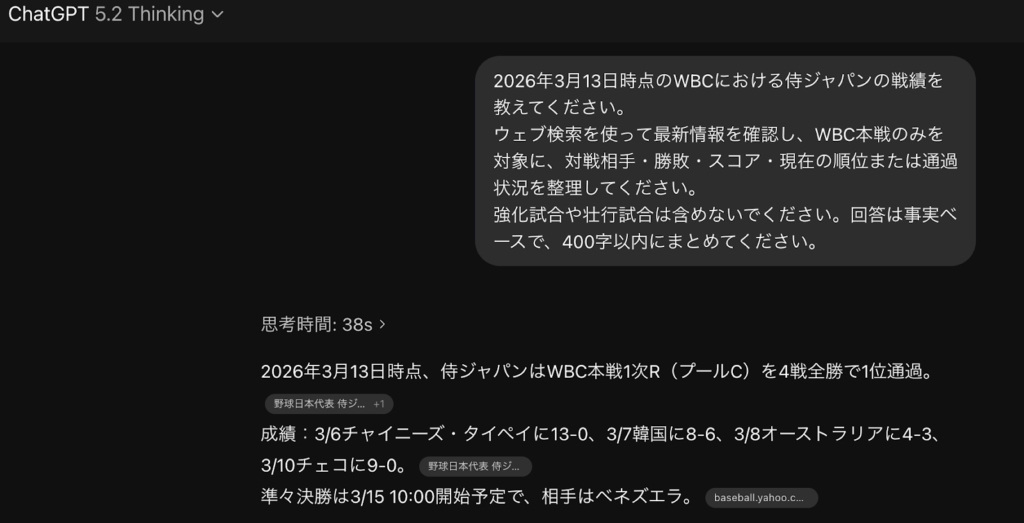
GPT-5.2 Thinkingの回答
引用:ChatGPT
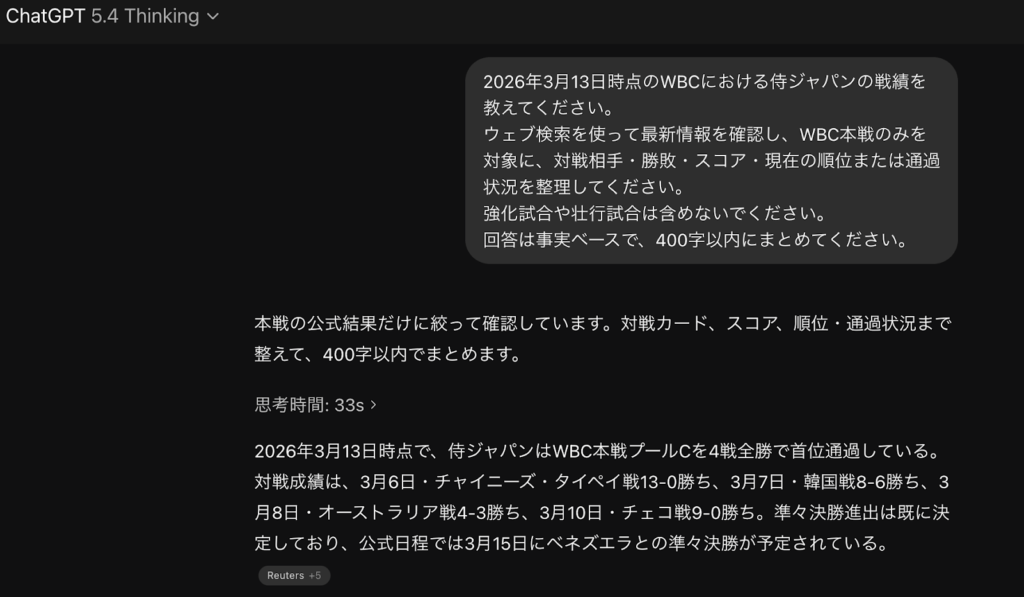
GPT-5.4 Thinkingの回答
引用:ChatGPT
結果として、両モデルの回答は正答かつ一致した。
いずれも、侍ジャパンがプールCを4戦全勝で首位通過していること、チャイニーズ・タイペイ、韓国、オーストラリア、チェコとの対戦結果、さらに3月15日にベネズエラとの準々決勝が予定されていることまで正しく整理できていた。
少なくともこの検証に限れば、GPT-5.4 Thinkingだけが優位性を見せたとは言いにくい。5.2 Thinkingの時点でも、ウェブ検索を通じて最新のスポーツ結果を正確に取得し、条件に沿って簡潔にまとめる水準にはすでに達していたからだ。
GPT-5.4ではハルシネーション抑制や検索能力の強化が打ち出されているものの、すべての題材で5.2との差が目に見える形で表れるわけではない。
今回のように、答えるべき情報が比較的明確で、検索先の信頼できる情報源にもたどり着きやすいケースでは、5.2 Thinkingでも十分に正解へ到達できる。
この検証で見えたのは5.4の圧勝ではなく、5.2 Thinkingの時点でも検索を伴う基本的な事実確認はかなり高い水準にあったということだ。
その意味で、今回の検証に関しては、GPT-5.4 Thinkingで劇的な差が現れたとは言いにくい。
少なくとも、最新の試合結果を検索し、事実ベースで簡潔に整理するという比較的シンプルなタスクにおいては、5.2 Thinkingの完成度もすでに高かった。
言い換えれば、GPT-5.4 Thinkingの進化は「簡単な検索課題でも一目でわかる飛躍」というより、既存の高水準な性能をさらに安定させ、より複雑な状況で差が出やすくなる方向の改善と見るのが自然だろう。
今回の結果からは、GPT-5.4 Thinkingが万能に大差をつけるというより、基本性能がすでに高い土台の上で磨き込みが進んでいることが読み取れる。
検証で見えたGPT-5.4の方向性 「賢さ」より「実務での有用性」へ
今回の検証を通じて見えてきたのは、GPT-5.4の進化が、単なる性能競争の延長線上にあるものではないという点だ。
もちろん、ベンチマーク上ではハルシネーション抑制や知識業務、コンピュータ操作、ウェブ検索、コーディング性能の改善が確認できる。
ANYCOLORの決算資料を用いた検証では、GPT-5.4 Thinkingは長い資料の中から数字、背景、リスク、見通しを整理し、決算の本質を順序立てて説明できていた。
単に情報を抜き出すだけでなく、論点を再構成し、読み手に伝わる形へ整える力が高まっていることがわかる。
一方で、侍ジャパンの最新戦績を用いた検索検証では、GPT-5.2 ThinkingとGPT-5.4 Thinkingの間に大きな差は出なかった。
これは、基本的な事実確認の水準がすでに高かったことを示すと同時に、5.4の進化が単純な検索課題で劇的な差として現れるというより、より複雑な業務で安定性や再構成力として表れやすいことを示唆している。
言い換えれば、GPT-5.4は「急に何でもできるようになったモデル」ではない。
むしろ、すでに高水準にあった生成AIの能力を、実務の現場でより扱いやすく、より信頼しやすく、より安定して使える方向へ磨き込んだモデルと捉えるほうが実態に近いだろう。
OpenAIが5.4系を主に有料ユーザー向けに展開していることも踏まえると、今回のアップデートは、賢さそのものを誇示するというより、「仕事で使える体験」を上位価値として強化する動きとして理解するのが自然だ。
実際、OpenAIはGPT-5.4を業務用途向けモデルとして位置づけており、ChatGPTでは公開時点でGPT-5.4 ThinkingをPlus、Team、Pro向けに提供している。
こうした提供形態からも、より高度な実務体験を有料価値として打ち出す意図がうかがえる。
今後は、単発の回答精度を競う段階から、長文資料の整理、検索を伴う調査、ツール利用、成果物の構成といった実務の一連の流れをどこまで安定して支えられるかが、生成AIの競争軸になっていくだろう。
その競争相手として無視できないのがClaudeだ。
Anthropicは金融業界向けの「Claude for Financial Services」を前面に押し出しており、銀行、保険、資産運用、フィンテック領域でも活用を訴求している。
つまり競争は、単に「どちらが賢いか」ではなく、「どちらが現場で安全かつ実用的に使えるか」に移りつつある。
今回の検証でも見えたように、GPT-5.4は単純な課題で劇的な差を見せるというより、長文整理や実務的な再構成、複雑な作業で強みを発揮する方向へ磨き込まれている。
今後の焦点は、Claudeを含む競合が実務支援の深さや業界特化を進める中で、OpenAIがどこまで「仕事の現場で手放せないAI」という立ち位置を固められるかにあるといえる。
参考:
関連記事:
OpenAI、「GPT-5.4」公開 事実誤認33%減とAIエージェント性能を強化



