


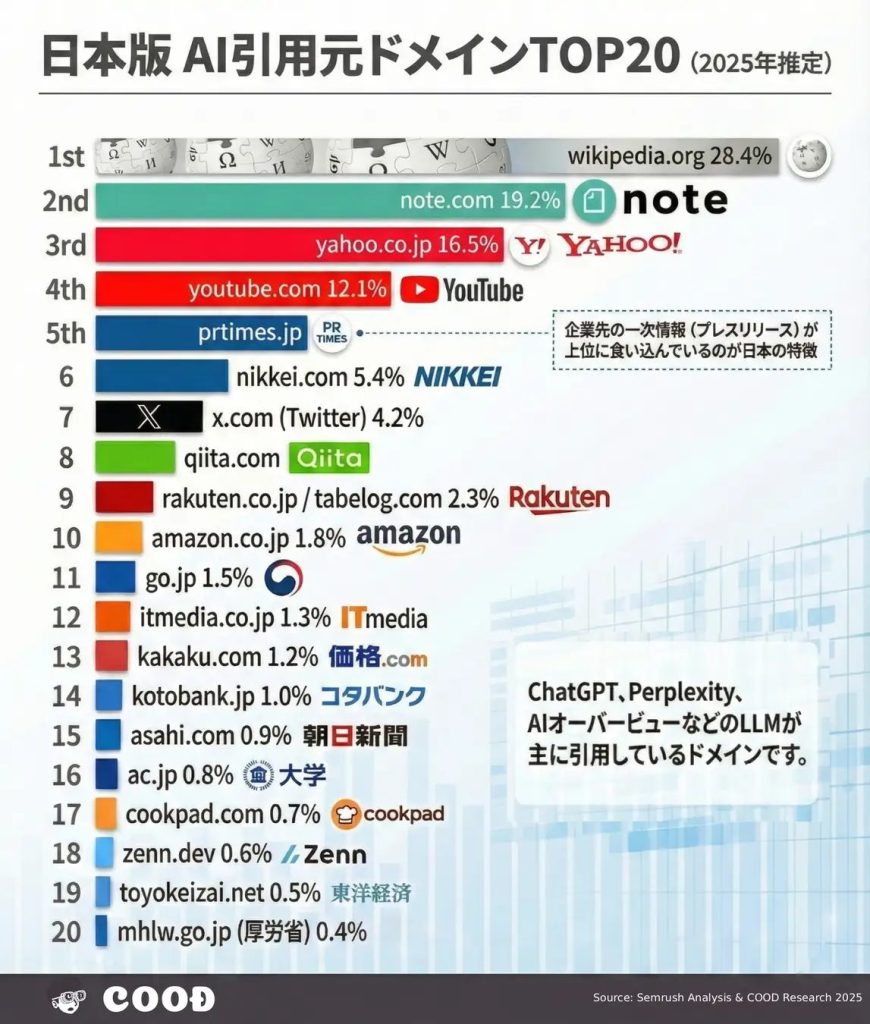
OpenAI、人間のエンジニアのような能力を評価する新たなベンチマークテストを発表

OpenAIは2025年2月19日、既存の評価基準とは一線を画す新しいベンチマーク「SWE-Lancer」を発表した。このベンチマークは、実際のフリーランス開発案件をベースとしており、コーディングに留まらず、よりプロのエンジニアに近い総合的な能力を評価する。
OpenAIのCEO、アルトマン氏は、人間のような判断力と行動力を持つAI「AGI」の創出を目指しており、このテストも、より人間的な総合能力を図る狙いがあると思われる。
参考 : 2025年にはAIが“労働市場に参加”する? サム・アルトマン氏が語る未来への展望
実務を反映した評価手法
従来のコーディングベンチマークは、単体のプログラミング課題や限定的なテストケースに基づいていた。一方、SWE-Lancerは実際のプラットフォームから収集した1,400以上のフリーランス案件を評価基準として採用している。
これらの案件は、50ドルの軽微なバグ修正から32,000ドルの大規模な機能実装まで、幅広い難易度と規模をカバーしている。
SWE-Lancerは、開発プロセス全体を通した総合的なテスト方式を採用している。
従来の単体テストが個々のプログラムの動作確認に留まっていたのに対し、問題の特定から、UIやUXのデザイン、デバッグ、修正の検証まで、実際の開発現場で行われる一連の作業全体を評価対象としている。設計やデザイン、プロジェクトマネジメントといったエンジニアの総合的スキルを測ることが目的だ。
現行AIモデルの実力と将来への目標
SWE-Lancerによる評価では、最新のAIモデルであっても、多くの課題を解決できないことが明らかになった。GPT-4oは8.0%、Claude 3.5 Sonnetは26.2%の課題解決率に留まり、マネジメント判断を要する課題では、最も高性能なClaude 3.5 Sonnetでも44.9%の成功率に留まっている。
現在のAIモデルは実務レベルのプログラミングタスクに対して、まだ発展段階にあるということだ。特に、開発に数十日単位の時間がかかる複雑な開発タスクは、AIはまだ得意としていない。AIモデルのシステム設計やアーキテクチャの決定といった高度な判断を要する作業には課題が残っている状況なのだ。
今回のベンチマークテストは、その弱点を評価対象に入れようとするものだ。
Open AI、そしてアルトマン氏の狙い
アルトマン氏は、人工汎用知能、AGIの開発を目指している。
AGIの目標は、人間と同等レベルのAIで、あらゆる知的業務を人間と同等にこなすことだ。
今回のベンチマークは、そのAGIを創出する上での目標設定であると言える。単なるコーディング能力ではなく、より「人間のプロエンジニア」に近い能力を持ったAIの創出を、OpenAI社は狙っているのだと思われる。

🚀 AI・Web3業界への転職を考えているあなたへ
「最先端技術に関わる仕事がしたい」「成長市場でキャリアを築きたい」そんな想いを抱いていませんか?
Plus Web3は、AI・Web3領域などテクノロジーに投資する企業の採用に特化したキャリア支援サービスです。
運営する株式会社プロタゴニストは、上場企業グループの安定した経営基盤のもと
10年以上のコンサルタント歴を持つ転職エージェントが
急成長する先端技術分野への転職を専門的にサポートしています。
こんな方におすすめです
▼成長産業であるAI・Web3業界で新しいキャリアを始めたい
▼「未経験だけど挑戦してみたい」という熱意がある
▼今のスキルを最先端技術分野でどう活かせるか相談したい
▼表に出ない優良企業の情報を知りたい
業界に精通したキャリアアドバイザーが、
あなたの経験・スキル・志向性を丁寧にヒアリングし、
最適な企業とポジションをマッチングします。






