


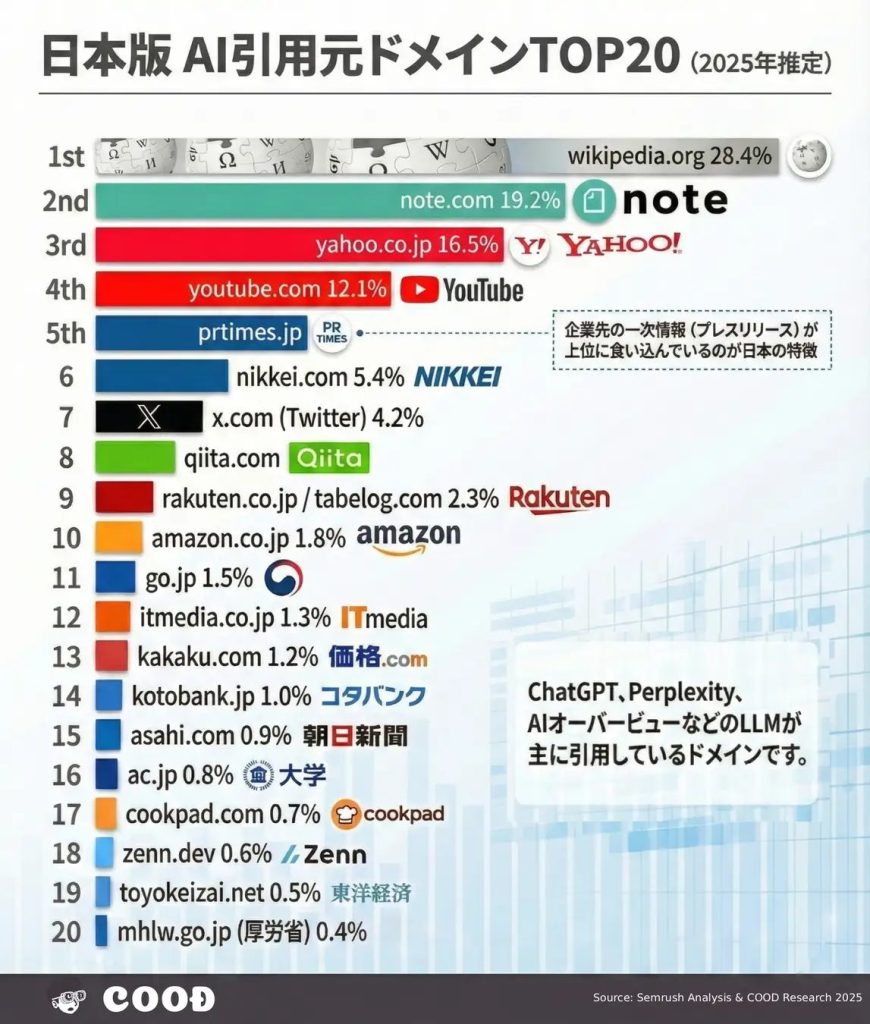
メタ、AI訓練に海賊版サイトを利用 違法データ使用が裁判文書で明らかに

米メタが開発した大規模言語モデル「Llama 3」の訓練に、海賊版サイト「Library Genesis(LibGen)」のデータが使用されていたことが判明した。この事実は、3月19日に公開された著作権侵害を訴える集団訴訟の裁判文書を通じて明らかになったものだ。
裁判の行方次第では、業界全体のあり方が大きく変わる転換点となるかもしれない。
メタのAI訓練と違法データの使用
LibGenは、750万冊以上の書籍と8100万本の論文を違法に提供しているサイトであり、科学、技術、工学、数学の分野に加え、美術館やアーティスト、建築家の書籍も含まれる。
学術界では一部で研究資料として活用されることもあるが、多くの国で著作権侵害と見なされている。
裁判文書によれば、メタのCEOであるマーク・ザッカーバーグ氏は、同社のシニアスタッフに対し、LibGenからデータを取得しAI訓練に使用することを許可していたとされる。
これにより、メタは迅速に高品質なデータセットを確保し、AIの性能向上を図ろうとしたと考えられる。
この問題が公になったのは、著名なコメディアンであるサラ・シルバーマン氏をはじめとする複数の著者が、メタに対して著作権侵害を訴える集団訴訟を起こしたことがきっかけだ。
原告側は、メタが著作権を無視し、無断で書籍をAIの訓練に利用したと主張している。
AIモデルの訓練において、書籍のデータはウェブ上の一般公開情報よりも価値が高いと考えられており、メタもその点を認識していたという。
しかし、著作権者と正式な契約を結ぶことなく、違法にアップロードされたデータを利用した点が大きな問題とされている。
メタの主張とAI開発への影響
メタは著作権侵害の指摘に対し、AI訓練におけるデータ使用は「フェアユース(※)」に該当すると主張している。しかし、商業目的で開発されているAIモデルにこの原則が適用されるかどうかは議論の余地がある。
著作権者側は、AIの訓練目的であっても、大量の書籍を無断で使用する行為は著作権法の趣旨に反すると反論している。特に、LibGenのような違法アップロードサイトのデータを活用することは、正規の著作権ビジネスに深刻な影響を及ぼしかねない。
この問題は、AI開発企業と著作権者の対立を象徴する事例としても注目されている。
仮にメタ側の主張が認められれば、他のAI企業も同様の手法を採用し、著作権の枠組み自体が変化する可能性がある。
一方で、著作権者側の訴えが通れば、AI開発企業はデータ収集の方法を大きく見直さざるを得なくなるだろう。
また、法整備の観点からも、各国でAI訓練に関する新たなルールが設けられることが予想される。これにより、著作権者とAI企業がライセンス契約を結び、適切な対価を支払うモデルが進展するかもしれない。
今後、裁判の進展とともに、AI開発における知的財産のルールがどのように変化していくのかが注目される。
※フェアユース:著作権法の例外規定で、一定の条件下で著作物を許可なく使用できる。ただし、商業的な利用や原作の価値を損なう場合は適用されにくい。

🚀 AI・Web3業界への転職を考えているあなたへ
「最先端技術に関わる仕事がしたい」「成長市場でキャリアを築きたい」そんな想いを抱いていませんか?
Plus Web3は、AI・Web3領域などテクノロジーに投資する企業の採用に特化したキャリア支援サービスです。
運営する株式会社プロタゴニストは、上場企業グループの安定した経営基盤のもと
10年以上のコンサルタント歴を持つ転職エージェントが
急成長する先端技術分野への転職を専門的にサポートしています。
こんな方におすすめです
▼成長産業であるAI・Web3業界で新しいキャリアを始めたい
▼「未経験だけど挑戦してみたい」という熱意がある
▼今のスキルを最先端技術分野でどう活かせるか相談したい
▼表に出ない優良企業の情報を知りたい
業界に精通したキャリアアドバイザーが、
あなたの経験・スキル・志向性を丁寧にヒアリングし、
最適な企業とポジションをマッチングします。






