
2025年、音声AIの進化が進み人間と見分けがつかないほど自然なAI音声合成(TTS)や、瞬時に言語の壁を超えるAI吹き替え技術は、エンターテイメントからビジネスコミュニケーションまで、その可能性を急速に広げています。しかし、AIが真に人間と円滑な対話を行うためには、「話す」能力だけでなく、人間の言葉をリアルタイムかつ正確に「聞く」能力が不可欠です。従来の音声認識技術は、遅延や精度の問題から、AIとの自然な会話の「壁」となっていました。音声AIのリーディングカンパニーであるElevenLabsが発表した「Scribe v2 Realtime」は、この根本的な課題を解決する可能性を秘めています。本記事では、このリアルタイム音声認識技術がAIの未来にどのような変革をもたらすのかを解き明かすため、本プロジェクトの詳細を考察します。
急速に進化する音声AIとElevenLabsのビジョン

生成AIの世界において、「音声」は今、最もダイナミックな進化を遂げている領域の一つです。単に録音されたテキストを読み上げる機械的な音声は過去のものとなり、現在では人間の感情の機微や話し方のクセ、さらには声色そのものをリアルに再現するAI音声合成技術が現実のものとなっています。この技術革新の中心にいる一社が、音声AIの研究開発企業であるElevenLabsです。彼らが目指しているのは、単なる高品質な音声ツールを提供することではなく、AIが生成した音声と人間の声との区別が本質的につかなくなるレベルの「人間らしい」音声コミュニケーションを実現することにあると推察されます。
ElevenLabsは、テキストから極めて自然な音声を生成する「Text to Speech(TTS)」や、元の話者の声質を保ったまま多言語に翻訳する「AI吹き替え(Dubbing)」といった技術で、すでに業界をリードしています。彼らの技術の根底にあるのは、AIとの対話における「遅延(レイテンシ)」を極限まで削減し、シームレスなコミュニケーションを実現するという強い意志です。AIがどれほど賢く、どれほど人間らしい声で話せたとしても、応答までに数秒の「間」があれば、それは自然な対話とは言えません。この「リアルタイム性」へのあくなき追求こそが、ElevenLabsの技術的優位性の源泉であり、彼らが音声AIの未来を形作る上で最も重要視している哲学であると言えるでしょう。
参考ページ:https://elevenlabs.io/realtime-speech-to-text
ElevenLabsが実現する「超リアル」な音声生成技術
ElevenLabsが音声AI分野で高い評価を得ている背景には、単一の機能ではなく、「話す」「聞く」「変換する」という音声コミュニケーションの核となる複数の高度な技術群が存在します。これらの技術が有機的に連携することで、これまでのAIのイメージを覆すような自然な体験を生み出しています。本項では、同社の中核をなす3つの音声生成技術について、その特徴を解説します。
感情豊かな「声」を創出するText to Speech
ElevenLabsのText to Speech(TTS)技術は、入力されたテキストを単に音声化するだけにとどまりません。その最大の特徴は、生成される音声に豊かな「感情」と「抑揚」を込められる点にあると考えられます。ソースによれば、同社のモデルは、喜び、怒り、悲しみといった感情表現はもちろん、会話の文脈に応じた微妙なニュアンスやイントネーションの違いまでを制御できる能力を持っているとされています。ゲームのキャラクターに命を吹き込むセリフ、オーディオブックでの臨場感あふれるナレーション、あるいはAIアシスタントの温かみのある応答など、コンテンツの没入感を飛躍的に高めることが可能になります。既存の合成音声ライブラリだけでなく、次に紹介するクローニング技術や、後述するVoice Labでゼロからデザインされた声を使える柔軟性も、クリエイターにとって大きな魅力となっています。
個性をデジタルに再現する技術Voice Cloning
同社の「Voice Cloning(音声クローニング)」は、音声AIの可能性を最も象徴する技術の一つです。これは、わずかな音声サンプル(から、その話者の声質、アクセント、特有の話し方といった「声の個性」を学習し、デジタルボイスとして再現するものです。この技術により、例えばコンテンツ制作者が自身の声を多言語対応させたり、病気などで声を失った人がデジタルの形で自身の声を取り戻したりといった、従来では考えられなかった応用が期待されます。もちろん、この技術は悪用のリスクもはらんでいますが、ElevenLabsは倫理的な利用ガイドラインを設け、生成された音声がAIによるものであることを示すための仕組みなども導入していると見られ、技術の恩恵とリスク管理の両立を図っている姿勢がうかがえます。
声の「スタイル」を自在に操るSpeech to Speech (STS)
「Speech to Speech(STS)」は、TTSやクローニングとは異なる、もう一つの革新的な技術です。これは、ある音声(入力)の「スタイル」—つまり、感情、抑揚、リズム、声色—を抽出し、それを全く異なるテキスト(内容)の読み上げに適用するものです。例えば、ある人が情熱的にスピーチしている音声を入力し、その「情熱的なスタイル」だけを借りてきて、別のテキストをAIに読ませることが可能になると解釈できます。ソースによれば、このSTSもリアルタイムでの処理が可能であり、AIアバターがユーザーの話し方をリアルタイムで模倣したり、あるいはユーザー自身の声の感情を増幅させてAIに代弁させたりといった、よりインタラクティブで表現力豊かなコミュニケーションが実現すると期待されます。
「Scribe v2 Realtime」がもたらすリアルタイム文字起こしの革新
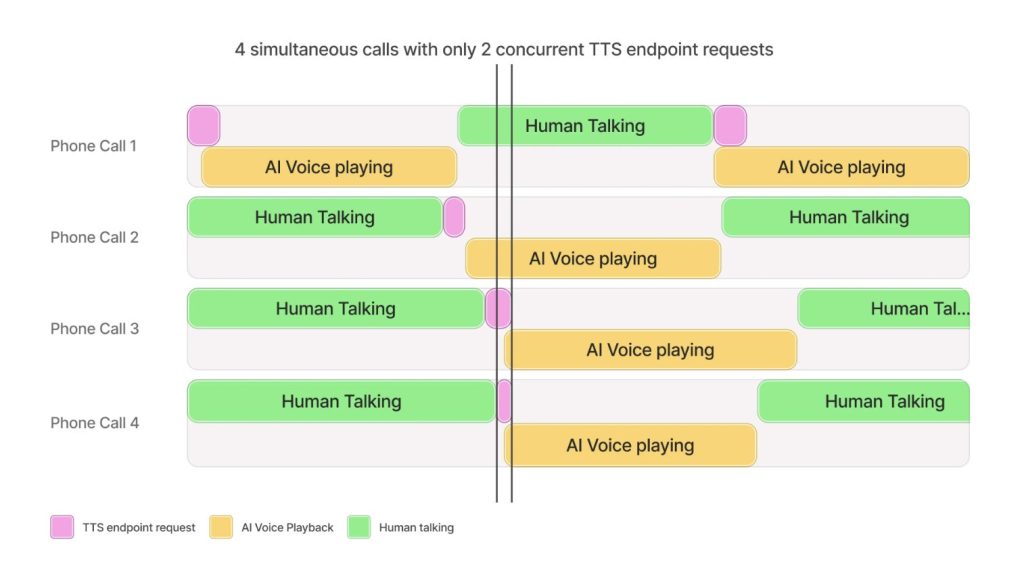
ElevenLabsはこれまで、「話す」能力(TTS)や「変換する」能力(STS、Dubbing)で業界を牽引してきましたが、AIとの自然な対話を実現するためには、もう一つの重要なピース、すなわち「聞く」能力が不可欠でした。その答えとして提示されたのが、同社のSpeech to Text(STT)技術の最新版、「Scribe v2 Realtime」です。この技術は、AIの「耳」の性能を新たな次元へと引き上げる可能性を秘めています。
「Scribe v2」の圧倒的な文字起こし精度
「Scribe v2 Realtime」の基盤となっているのは、まずその圧倒的な文字起こし精度です。ソースによれば、「Scribe v2」は99%以上という非常に高い精度で音声ファイルをテキストに変換できる能力を持つとされています。これは、専門用語が飛び交うビジネスカンファレンス、方言やノイズが含まれるインタビュー、あるいは早口のポッドキャストなど、多様なシチュエーションにおいて、人間の聞き取り能力に匹敵する、あるいはそれを超えるレベルの正確性を発揮することを示唆しています。この高精度が担保されて初めて、AIは人間の言葉を「正しく理解」し、適切な応答を返すことが可能になります。従来のSTT技術で頻発していた誤認識によるコミュニケーションの齟齬が、劇的に改善されることが期待されます。
リアルタイム処理が拓く新たな可能性
Scribe v2の「Realtime」版が持つ最大の価値は、その名の通り「リアルタイム性」にあります。従来の文字起こしは、音声ファイル全体を一度サーバーにアップロードし、処理が終わるのを待つ「バッチ処理」が一般的でした。しかし、Scribe v2 Realtimeは、話された言葉がほぼ同時にテキスト化されていく「ストリーミング処理」を実現しています。AIが人間の発話を「聞き終わる」のを待つ必要がなく、会話の途中でさえも次の応答の準備を始めることが可能になります。この「瞬時の理解」は、AIアシスタントやAIエージェントとの対話において、人間同士の会話のような自然なテンポとリズム感を生み出すための鍵となります。遅延のない文字起こしは、AI対話の「壁」を取り払う第一歩と言えるでしょう。
WebSocket APIによるシームレスな対話体験の実現
このリアルタイム性を技術的に支えているのが、開発者向けに提供される「WebSocket API」であると推察されます。WebSocketは一度確立した接続を維持し、双方向でデータを継続的にやり取りできる技術です。ElevenLabsがリアルタイムTTS/STS/STTのためにWebSocketを重視しているとみられ、Scribe v2 Realtimeにおいてもこの技術が採用されていることで、開発者は、ユーザーがマイクに向かって話し始めた瞬間から音声データをElevenLabsにストリーミングし、ほぼ同時に文字起こし結果を受け取り、即座にそのテキストを大規模言語モデル(LLM)に渡し、返ってきた答えを同社のTTS APIで音声化する…といった、一連の複雑なプロセスを、極めて低い遅延でシームレスに構築することが可能になります。
開発者エコシステムとプラットフォームとしてのElevenLabs
ElevenLabsの強みは、個々のAIモデル(TTS、STS、STT)が高性能であることだけに留まりません。同社は、これらの強力なツール群を開発者が容易に自社のサービスやアプリケーションに組み込めるよう、洗練されたプラットフォームとAPIエコシステムを提供しています。この「プラットフォーム戦略」こそが、同社が音声AIの分野で急速に存在感を高めている大きな理由であると考えられます。開発者はRESTful APIとWebSocket APIという2種類の主要なインターフェースを通じて、ElevenLabsのほぼ全ての機能にアクセスできるとされています。特にWebSocket APIは、今回のテーマである「Scribe v2 Realtime」や、リアルタイムTTSなど、瞬時の応答性が求められるユースケースのために最適化されており、開発者が次世代の対話型AIエージェントやリアルタイム翻訳アプリを構築する上での技術的基盤となっています。
さらに、同社は、ユーザーが独自の音声クローンを作成したり、年齢、性別、アクセントなどを細かく調整して全く新しいAI音声を「デザイン」したりすることを可能にしています。また、プロのデザイナーによって作成された高品質な既製音声が多数用意されており、開発者は自分のプロジェクトに最適な声をすぐに見つけて利用することができます。 加えて、動画コンテンツの多言語展開を効率化するツールも提供しており、元の話者の声の特徴を維持したまま、様々な言語に吹き替えが可能とされており、グローバルなコンテンツ配信のハードルを大きく下げています。 このように、ElevenLabsは単なる音声合成や音声認識の「部品」を提供するだけでなく、それらを組み合わせて新しい価値を生み出すための「開発基盤」そのものを提供しているのです。「Scribe v2 Realtime」の登場は、このプラットフォームに強力な「耳」を追加することで、そのエコシステムをさらに強固なものにしたと言えるでしょう。
今後の展望
生成AIの登場から数年、企業の業務現場でもAI活用は急速に進みつつあります。特に音声AIの進化は目覚ましく、AIが人間のように「話す」能力は急速に向上してきました。しかし、AIが真に企業活動や私たちの日常の中核を担うためには、「話す」能力と対になる「聞く」能力、すなわちリアルタイムで正確な音声認識(STT)が不可欠です。ElevenLabsの「Scribe v2 Realtime」のような高精度リアルタイムSTTの登場は、AIが単発の支援ツールにとどまらず、業務の中で継続的に「聞き、理解し、話す」存在へと進化するための重要な一歩となります。
リアルタイムSTT/TTSが実現する「遅延のないAIエージェント」
Scribe v2 Realtimeがもたらす最大のインパクトは、AIエージェントやAIアシスタントとの「対話品質」の根本的な向上にあると考えられます。従来の対話型AIは、私たちが話し終えてからAIが応答を返し始めるまでに、数秒の「待ち時間(遅延)」が発生するのが一般的でした。この遅延の多くは、①音声認識(STT)の処理時間、②大規模言語モデル(LLM)の思考時間、③音声合成(TTS)の処理時間、という3つのステップで発生していました。 ElevenLabsは、Scribe v2 Realtime(STT)と、同社の超低遅延TTSを組み合わせることで、このうちの①と③の時間を極限まで短縮する道筋を示しました。特にSTTがリアルタイム(ストリーミング)で実行できるようになったことの意味は非常に大きいです。AIは私たちが「話し終わる」のを待つ必要がなく、話の途中でさえも、ほぼ同時にテキスト化された内容をLLMに送り、思考を開始させることが可能になります。 将来的には、人間が言葉を発している間に、AIがその意図を先読みし、応答を準備し、人間が話し終えた瞬間に、まるで相槌を打つかのように自然に応答を返し始める、といった真に「遅延のない」対話が実現するでしょう。これは、カスタマーサポートのAIオペレーター、会議のファシリテーターAI、あるいは日常の話し相手となるAIコンパニオンなど、あらゆる対話型AIのユーザー体験を、現在の「命令と応答」の関係から「自然な会話」の関係へと劇的に引き上げることにつながると推察されます。
多言語の壁を超える「リアルタイムAI同時通訳」の実現
ElevenLabsは、既に「AI Dubbing Studio」によって、元の話者の声質を維持したまま動画コンテンツを多言語化する技術を提供しています。Scribe v2 Realtimeの登場は、この「吹き替え」技術を、録音されたコンテンツから「リアルタイムの会話」へと拡張する可能性を秘めています。 想像してみてください。国際会議やオンラインミーティングにおいて、自分が母国語で話した内容が、瞬時にScribe v2 Realtimeによって高精度でテキスト化されます。そのテキストが即座に翻訳API(LLMなど)に渡され、翻訳されたテキストがElevenLabsのリアルタイムTTS(Speech to Speech技術を応用すれば、自分の声質を維持したまま)によって相手の言語で音声化される。これが双方向で、数秒の遅延もなく行われる世界です。 Scribe v2 Realtimeの高精度とリアルタイム性は、この「AI同時通訳」の品質を左右する最も重要な「入り口」となります。聞き取りミスが多発したり、翻訳に時間がかかったりすれば、会話のテンポは失われ、実用には耐えられません。Scribe v2 Realtimeのような技術は、言語の壁によって阻害されてきたグローバルなコミュニケーションを根本から変革する可能性を持っています。これは単なるビジネスの効率化を超え、異なる文化間の即時的な相互理解を促進し、国際交流や教育、エンターテイメントのあり方そのものを変容させるインパクトを持つと期待されます。
Scribe v2 Realtimeによる「会議・教育のアクセシビリティ革命」
高精度なリアルタイム文字起こし技術の恩恵は、AIエージェントや翻訳といった未来的な応用だけに留まりません。Scribe v2 Realtimeは、「聞く」ことに困難を抱える人々にとってのアクセシビリティを向上させるツールとなり得ます。 例えば、聴覚に障害を持つ人々にとって、会議、講義、あるいは日常の会話の内容をリアルタイムで正確に把握することは、長年の課題でした。Scribe v2 Realtimeのような技術をスマートフォンやPCに搭載することで、目の前で話されている内容が、ほぼ遅延なく、高精度な字幕として画面に表示されるようになります。情報から取り残されることなく、議論や学習に完全に参加することが可能になります。 また、この技術は教育現場においても革新的です。教授の講義内容がリアルタイムでテキスト化されれば、学生はノートを取る作業から解放され、講義内容の理解により集中できます。さらに、テキスト化されたデータはそのまま検索可能な学習資料となり、後で特定のキーワードを元に講義内容を即座に振り返ることも可能になります。Scribe v2 Realtimeの精度は、特に専門用語が多く登場する高等教育や医療、法務といった分野において、その価値を最大限に発揮するでしょう。このように、AIの「正確な耳」は、情報格差を埋め、より公平で包括的な社会参加と学習環境を実現するための基盤技術となると考えられます。


